Steve G
-
Posts
745 -
Joined
-
Last visited
-
Days Won
30
Content Type
Profiles
Forums
Enhancement Requests
Everything posted by Steve G
-

Microsoft Key creation
Steve G replied to Steven Cotterell's topic in Integration Connectors, API & Webhooks
Hi @Steven Cotterell, This is more of a Microsoft Graph restriction than Hornbill I'm afraid. The Graph API that posts a message to a Teams channel needs the Group.ReadWrite.All permission (and odd permission, granted, but this is Microsoft...), and this specific permission requires admin consent during the login/oAuth process. See the Microsoft permissions documentation for more information: https://docs.microsoft.com/en-gb/graph/permissions-reference Now, the Graph API we're using to post to a channel (https://docs.microsoft.com/en-us/graph/api/channel-post-messages?view=graph-rest-beta&tabs=cs) is still in beta, and subject to change, so I wouldn't be surprised if the required permissions become more relevant (and hopefully no longer requires admin consent) when Microsoft promotes this to production. If/when that happens, I'll create a Teams-specific keysafe key type with permissions locked-down to just those required to perform the Teams actions. Will bookmark this post and let you know when that gets done Cheers, Steve- 15 replies
-
- 2
-

-
- keysafe
- integration
- (and 1 more)
-
example Teams to Hornbill via Flow
Steve G replied to Steve G's topic in Integration Connectors, API & Webhooks
Hi @samwoo, Thank you Was great meeting you both too. That's a good suggestion - I think this sub-forum is probably the correct place for this type of content, but adding tags to the posts might be a good way to easily search and retrieve them? Would save on having a separate sub-forum, or using a third-party tool like Github Gists... I'll have a think about suitable tags, and get that set up! Cheers, Steve -
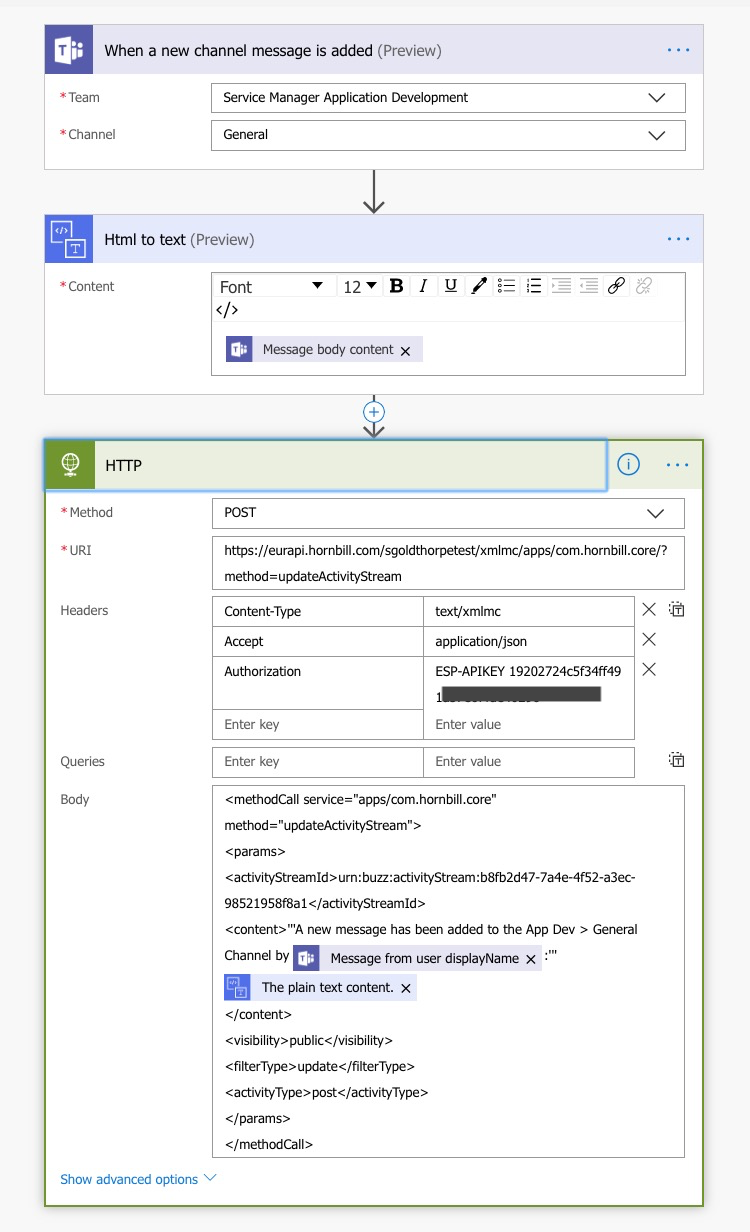
Morning @Martyn Houghton @Dan Munns @Malcolm One of the questions on the Integration Round Table yesterday was: Can we write to a Hornbill Activity Stream (workspace) when a message has been added to a channel on Microsoft Teams? The answer is yes I've knocked up an example flow to demonstrate how that could work for you: You just need to replace the instance ID in the URI with that of your instance, the Authorization header needs a valid API key for an account that can write to the activity stream, and of course the activityStreamId in the body will need replacing with yours And this is what was written to the workspace in Hornbill: Note I'm using the HTML to Text node to strip out any HTML tags from the comment, as un-encoded HTML in the XML payload would cause the API call to fail. Hope this helps, Steve

-
Hi @Izu, The changelog is in the repository on Github: https://github.com/hornbill/goLDAPUserImport/blob/master/CHANGELOG.md Thanks, Steve
- 1 reply
-
- 1
-

-
Hi @Martyn Houghton, If you clear the "Member Of" field, then all found users should be added to the idoxgroup Company. Cheers, Steve
-
failing Google Integration issue
Steve G replied to Jeremy's topic in Integration Connectors, API & Webhooks
Hi @Jeremy, I've found and fixed the issue. There was a scenario we hadn't catered for when attempting to refresh the access token - the Google API was returning an unexpected error message back. I've catered for both now, and tokens refresh as expected. Give it 5 minutes and it'll be on your instance. Note - you don't have to do anything at your end, it should just start working Cheers, Steve -
Form created using Flow
Steve G replied to Shamaila.Yousaf's topic in Integration Connectors, API & Webhooks
Hi @Shamaila.Yousaf, This will be a problem in the config of the HTTP action within the flow, or a previous form parsing node injecting incorrect data into your parameters. There are some details on configuring the HTTP action within Flow in this post: If you pass this information on to your Flow designer, they may be able to use this to fix the Flow. Cheers, Steve -
Calling a service in the API Sandbox from C#
Steve G replied to jeffgleed's topic in Integration Connectors, API & Webhooks
Hi @jeffgleed, Looks like the error is thrown because the first param is incorrect when initialising a new XmlmcService object. This should be set to the ID of your Hornbill instance, and not https://api.hornbill.com. Re: your second point, leave it with me and I'll get back to you on that. Cheers, Steve -
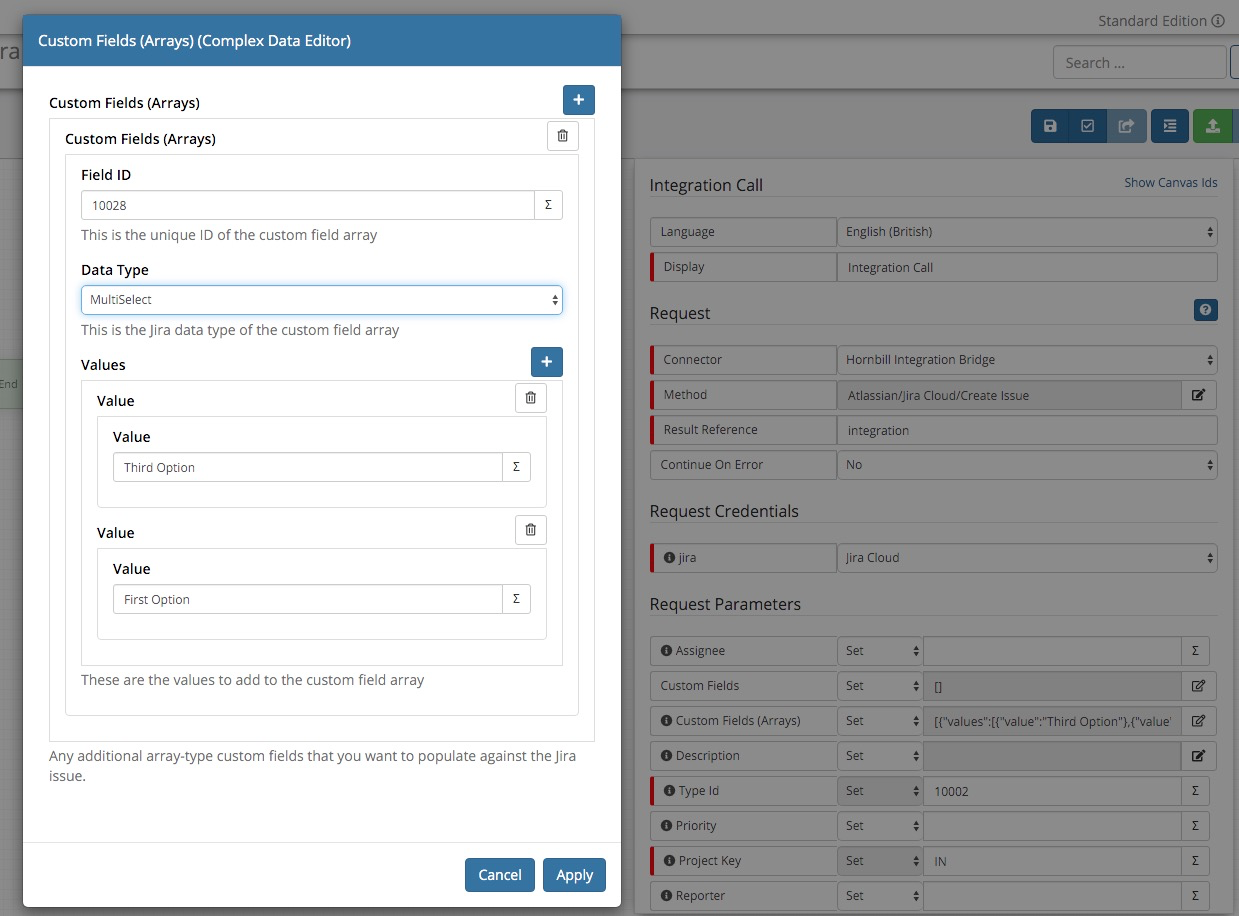
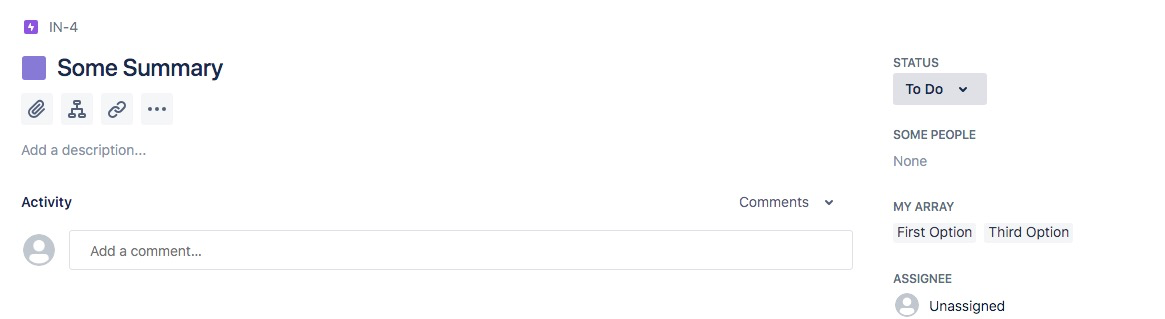
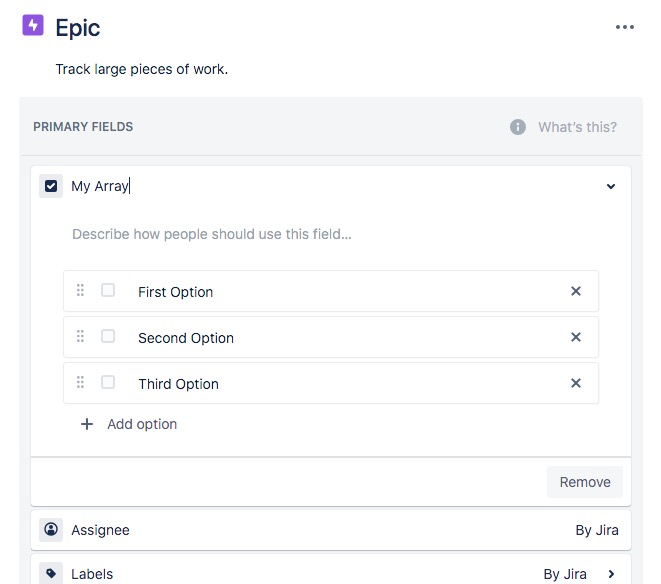
Hi @HHH, The Jira and Jira Cloud integrations for Create Issue and Update Issue now support custom fields of type array. On the integration methods, there is a new Request Parameter called Custom Fields (Arrays) , which when configured will add the relevant custom field data to the API call to Jira. For example, this will set the First Option and Third Option values against the multi-select item with the key of 10028 against any new issues created: As you can see in the issue generated: And the custom field defined as: The data types available to array-type custom fields are MultiGroupPicker, MultiSelect, MultiUserPicker and VersionPicker, as defined by Jira and should match the type of your custom field. See the Jira documentation for more information: https://developer.atlassian.com/server/jira/platform/jira-rest-api-examples/ Let me know how you get on with these enhancements. Thanks, Steve
-
Hi @Dan Munns, That's done and released to Github . There's a new boolean property as part of the Schedule in the config: DayOfMonthANDDayOfWeek Setting this to false will use the existing crontab standard expression parser. Setting this to true will use the existing parser, but will also check to see if the day of week AND day of month both match before executing the API call. Let me know how you get on with this. Cheers, Steve
-
Hi Dan, After looking at the code and re-reading the crontab specification, this is working as expected: http://pubs.opengroup.org/onlinepubs/7908799/xcu/crontab.html From the examples: I may be able to add some extra logic in the tool to cater for your use case though. I'll let you know once I've come up with a solution. Cheers, Steve
-
Hi @Dan Munns, I've been able to replicate this, it looks like the day of week and day of month values in the expression are applied with an OR instead of an AND. I'm just looking into the cron package now to see if there's anything we can do about that, will let you know when I have an answer. Cheers, Steve
-
Hi @Martyn Houghton, That's a good shout, I'll raise the suggestion and let you know the outcome. Cheers, Steve
- 4 replies
-
- 1
-
-
- api
- api.hornbill.com
- (and 3 more)
-
Hi @Martyn Houghton, I've just released v1.3.0 of the Hornbill Request Import tool, with the following features: Added support to import Releases Added MySQL 8.x support Can now map and resolve Catalog Items for Services, and to use the Catalog Item BPM workflow should one exist Can now set default Catalog Item if default Service is applied Can now set default owner alongside default team Added version flag for cross-compiling script support It's documented on its wiki page, and you can get the OS and architecture specific zips from Github. Notes regarding a couple of the points you requested: Add the additional custom fields which now go up to h_custom_t and h_custom_30. This is already supported, you just need to add the additional fields to the CoreFieldMapping and AdditionalFieldMapping columns Extend current supported request types, Incident & Service Request, to include all other types, i.e. Change, Problem, Known Error and Release. Aside from Release, this was already supported. You just need to copy & paste one of the other objects from within the RequestTypesToImport array and configure accordingly Support the import and matching of Sub Status, only current supports parent status. There's a lot of logic in Service Manager that handles stuff happening on the back of sub status changes, so this should be built into your workflows instead Support the import and matching of Service Level Agreement and Service Level's. Same as the Sub Status comment, above. Simplify the historic updates import section, to provide separate fields to indicate source, visibility, user etc, rather than using the Supportworks native bitwise format. This is legacy stuff to support Supportworks imports, and providing of the correct bitwise flag can be done in the SQL, so I'll add an example to the documentation rather than hard-code it in the tool Cheers, Steve
-
Hi @Martyn Houghton, Apologies, it looks like the build script missed the copy of the conf file. The release has been updated to include that now. Cheers, Steve
- 2 replies
-
- 1
-
-
- request cleaner
- conf.json
- (and 1 more)
-
Hornbill Cleaner utility fix
Steve G replied to Izu's topic in Integration Connectors, API & Webhooks
Hi @Izu, This has now been released. The OS and architecture specific release ZIPs can be downloaded from here: https://github.com/hornbill/goHornbillCleaner/releases/latest Note: this requires Service Manager build of at least 1459 to be running on your instance. Cheers, Steve -
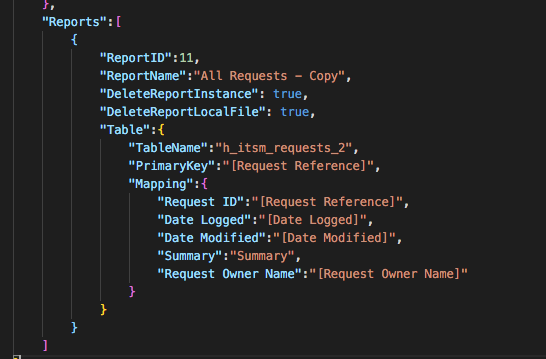
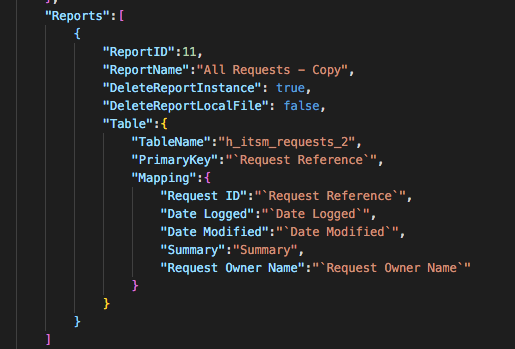
Hi @Joanne, This has now been fixed, you can now use square brackets to wrap column names for SQL Server column names that include spaces, or back-ticks to wrap column names for MySQL/MariaDB column names that include spaces. MS SQL Server example: MySQL/MariaDB example: Note, the left-hand property in the mapping is the Report column name property, and the right-hand values are the Database column name where the record values will be written in to. The Report column name properties can include spaces and don't need to be wrapped by any [] or `` characters. The latest release ZIPs can be found here: https://github.com/hornbill/goHornbillDataExport/releases/latest You just need to download the ZIP that is relevant to your operating system and architecture. Let me know how you get on with this. Cheers, Steve
-
Hi @Dan Munns, There was a duplicate task bug with the Go cron library used to build this tool, but was only evident on certain Windows builds - this was probably what was causing your issue. I've just released v1.2.1 of the tool that contains the latest cron library, which includes a fix for that issue. Could you download the OS-specific release ZIP from here and let me know if this fixes the issue for you? https://github.com/hornbill/goAPIScheduler/releases/tag/1.2.1 Cheers, Steve
-
Hi @Dan Munns, I'll have a look to see if I can replicate this, will get back to you with the results. Cheers, Steve
-
Hi @Martyn Houghton, This is because the tool is expecting the Service Manager Priority names to be entered in the property values (on the right-hand side of the PriorityMapping properties), and not the primary keys. I have noticed an enhancement that I need to make to that code though, which I'll include in the next release. I'm going through the other required changes currently, so should hopefully have a new release of this tool out in the next day or so. I'll let you know once released. Cheers, Steve
- 2 replies
-
- 1
-
-
- hornbill request import
- priority
- (and 1 more)
-
Hi @Martyn Houghton, I'm not able to replicate this issue locally with a properly defined configuration, connecting to a MySQL 8.0 data source (as I've been updating the source to work with this - should have a release out in the next couple of days) I'm able to pull and import all records from my test database. Do you have the tool configured to connect to the data source directly, or via ODBC? It's unlikely to be reserved characters causing the issue, as the driver should still be able to get at those records, and if not then an error would be written to the log during the unmarshalling of the record data. One scenario which may see this behaviour would be if the tool detects that the request record already exists in memory (as there's code to prevent duplication of imported requests). So if the value of the column defined in the RequestReferenceColumn property is not unique. What do you have defined in your incident import config, as does that match the request reference column in your source data? Thanks, Steve
-
Hornbill Request Import - Status OnHold
Steve G replied to Martyn Houghton's topic in Integration Connectors, API & Webhooks
@Martyn Houghton You would indeed be correct If the request being imported is in a cancelled, resolved or closed state, the BPM is not spawned. Cheers, Steve- 3 replies
-
- 1
-
-
- hornbill request import
- status
- (and 2 more)
-
Hornbill Request Import - Status OnHold
Steve G replied to Martyn Houghton's topic in Integration Connectors, API & Webhooks
Hi @Martyn Houghton, That's correct, the on-hold date/time should be added to the h_dateclosed field. Cheers, Steve- 3 replies
-
- 1
-
-
- hornbill request import
- status
- (and 2 more)
-
@Martyn Houghton, Will get that included, thanks. Cheers, Steve
- 12 replies
-
- 1
-
-
- request types
- service level
- (and 2 more)
-
Just to close this off, this is now fixed, details here: Cheers, Steve