Victor
-
Posts
5,694 -
Joined
-
Last visited
-
Days Won
169
Content Type
Profiles
Forums
Enhancement Requests
Everything posted by Victor
-
I think there is a misunderstanding here on how intelligent/progressive capture works and what is intended for and how business process works and what is intended for. But no, you cannot have a value captured from a (random) task in a (random) workflow to be used as a value in a (random) intelligent capture in a (random) custom form and field... the "randoms" are because for what is described here, they are exactly that: random. Firstly, the PC is functionality that is used before a request is raised. It captures data from a user. The BP is functionality that is used after a request is raised. It automates and drives the request. Thus having "something" that we obtain in an "after" process to be used in a "previous" process is simply not possible. Second, we can then say sure, use the data from the BP to be used in the "next" PC... ok, but what is this "next"? Out of all the definitions you have in your instance, what PC would that be? And looking from the other perspective, in PC, from what workflow we would get this BP value? Is the data gathered in workflow 1, 2 or 3? This out of all the running workflows an instance can have... Perhaps a more practical example of how this discussion came to be might help understanding a bit better what we try to achieve here but using workflow data feeding capture data is impossible.
-

How to use Human task outcome to make decision on next stage?
Victor replied to lee mcdermott's topic in Service Manager
Not by using the task itself... As @Paul Alexander suggested you would need to store this value on the request (directly or indirectly) to have the human task value available in another stage. -
Capture API response not just status
Victor replied to Dan Munns's topic in Integration Connectors, API & Webhooks
@Dan Munns what I mean is that is the extent of what I can do on this Does this mean that I don't have a make it so button? Maybe I don't. Or maybe I do but I can't use it. Or maybe I do but I won't use it... possibilities... possibilities -
Capture API response not just status
Victor replied to Dan Munns's topic in Integration Connectors, API & Webhooks
@Dan Munns I can tag this thread as enhancement request but that's the extent of what I can do on this... -
Additional Regional Laungage - swedish
Victor replied to Dave Longley's topic in System Administration
@Dave Longley what exactly do you mean by "adding in another additional language"? Only functionality I can think of is translations and you can add the Swedish translation in Platform Configuration: Switch the drop-down to "unsupported" to have locate Swedish, enable it and it will then be displayed as "supported" and can make translations in this language in user app...
-
@JakeCarter looking at the measure configured, would that be over 6 months? A year? Or since the beginning?
-
Capture API response not just status
Victor replied to Dan Munns's topic in Integration Connectors, API & Webhooks
It can be built if requested... Sure... but there are other downsides or one more downside... in my view, the most important one that this functionality can simply disappear one day... not saying it will, no plans to do this as we speak as far as I am aware of, but the possibility is always there... so, my advice, once again, do not use this in a production capacity. Yes, I do understand it fills a gap in functionality... but the troubles of "fixing" workflows in case of this being removed might outweigh the benefits it provides now... -
Capture API response not just status
Victor replied to Dan Munns's topic in Integration Connectors, API & Webhooks
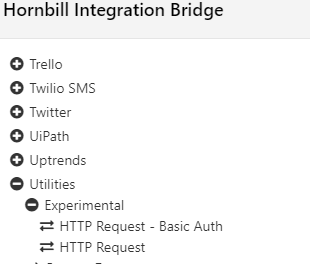
Are we talking about these Experimental methods? If yes, I would recommend not relying on them in a production capacity...
-
@Jake Carter not completely... you need :: Value Aggregate: Count This will remove Value Column as Count does not use this. Everything can stay the same. Change the value aggregate, resample and see what data is bringing then...
-
@Malcolm simply put, no. I do understand the requirement and where this comes from but current functionality does not allow this type of measurement. In addition to what Steve said above, all I can say there is to describe the reason for this, even if this does not help with what you are trying to achieve, at least it explains why. Request timers can only be started by the "Start Request Timer" nodes. There is no other functionality in Hornbill that will start a request timer. You can most likely imagine now that regardless of how fast the request is raised, workflow spawned, node executes... there will always be a difference (no matter how small, can be minutes, seconds, milliseconds)... not only between when the request is raised (date logged) but also from when the respective mail arrives in the mailbox (even if is automatically raised by routing rule, more if a request is manually raised). Moreover, there is also no functionality to "move" the start time for a request timer...
-
Linked Requests Not using the correct Catalog Item
Victor replied to SJEaton's topic in Service Manager
@SJEaton you have a "Service" and "Copy Service"... these two conflict. Set "Copy Service" to Ignore (as you specify a service already) and give it another try. -
Feedback - rate our service to you unable to complete?
Victor replied to Adrian Simpkins's topic in Service Manager
@Alberto M next Service Manager update -
@Alisha what is a third party update in context of Hornbill? And how would this Third Party update the request? Directly/Indirectly?
-
Set up workflows for parent and linked requests
Victor replied to SJEaton's topic in Service Manager
@SJEaton the screenshots seem to be quite small unfortunately... any chance you can repost? -
issue Performance and other issues when editing Business Processes
Victor replied to samwoo's topic in Business Process Automation
@samwoo it would have been a "good night" for him most likely... update: Fixed (pending an update): moving node off canvas does not reposition groups or notes via connection nodes auto moving when moving nodes connected to them In Progress: performance (possibly memory leak) when editing complex workflows -
@CraigP for incoming emails, it would be the ones highlighted below: You can refine the above and exclude any that are not effectively in use: POP an/or IMAP.
-
Set up workflows for parent and linked requests
Victor replied to SJEaton's topic in Service Manager
@Paul Alexander they can class it as simple.. it's all about perspective... usability, setup and functionality, user perspective? Simple... design and code, development perspective? Well... :
-
@samwoo if your simple list contains any values that can be used in the "Get User Details" such as user ID, login ID or employee ID then you can make use of this node.
-
Set up workflows for parent and linked requests
Victor replied to SJEaton's topic in Service Manager
Yep, definitely worth exploring. Ideally one would just use a simple built-in node "Wait For All Linked Requests Resolution". If we only had one... -
@Joy @samwoo Yes. However if one needs other user data, e.g. full name, one can make use of this node: Put value returned by the task in the user ID param. Then have another node to update that custom T (or the custom field that you use) with the values returned by this node, e.g. display name, first name last name, etc.
-
Set up workflows for parent and linked requests
Victor replied to SJEaton's topic in Service Manager
@Paul Alexander doable... on top of my head 1. Have the main workflow in a Suspend Wait For Update - it will resume when an update is made on main request 2. From the linked request, when resolved, push an update for a custom field of the main request 3. From the linked request, when resolved, push an update on the main request, e.g. "Linked request 1 was resolved" or anything really, it just needs to be an update 4. Have the main workflow refresh request details and check the value for the custom field At this point 2 - 4 will be looping and 2 will be updating a different custom field for each linked request and step 4 would be configured to check values for all these custom fields. If not all values are set, loop back to Suspend Wait For Update. When all values are set, meaning all linked request resolved and updated their correspondent custom field in main request, continue the main workflow. Just an idea, might not be the best, and it would more or less work for a fixed number of linked requests. It also needs available custom fields in main request. One could possibly explore the option to update one custom field only by adding content to this field each time a linked request is resolved then perhaps check for this value in the main request, e.g. how many characters or similar are in the string... -
@Salma Sarwar The possibility of request being manual taken off hold will complicate things as the workflow needs to cater for this scenario as well. At this point I will have to refer this to an expert service with a product specialist as configuration can be very different. On top of my head one can make use of auto tasks to perform the off hold and other actions that would progress the workflow in a certain way or one can forego the solution/steps I suggested above and go for a "Wait For Request Off Hold" node (instead of "Wait For Update") and trigger the off hold from the child request: when the child request is resolved have an "Update Request Status" node that will update the parent request, effectively changing the status. I don't think this will actually resume the parent workflow so you also probably need to follow this with an "Update Request" on the parent request again to have the "Wait For Request Off Hold" resume. And this for the scenario when having one child request, if there are more this becomes more complicated. I would recommend scheduling a session with a product specialist to discuss and implement what you need to achieve in your workflow.
-
Set up workflows for parent and linked requests
Victor replied to SJEaton's topic in Service Manager
@SJEaton @Paul Alexander now I am very curious to see how is the setup where the workflow having a Wait For Resolution (with a linked request ID as input param) will resume at the time when the linked request is resolved... I really cannot see how this would work and I am sure I did look through all the code logic -
@Salma Sarwar there is an example, provided above: request B is raised as linked request to request A and request A is put on hold request B is resolved and the workflow is configured send an update to the linked request A once/after request B is resolved request A is on hold with the workflow in a suspend state waiting for an update which is received from request B request A is taken off hold by the workflow Implement this in your workflows and if any issues let us know
-
Set up workflows for parent and linked requests
Victor replied to SJEaton's topic in Service Manager
Has this been tested by any of you? Afaik, this will not work as you think it does and this is because how the suspend/resume works in the background. I'll try and give you a broad overview: one each (or most) actions performed on a request (e.g. update, resolve, escalate, email, etc.), the last bit the action does is invoking a "processResume" API. This API will retrieve the relevant workflow based on data from where the API was invoked (important). It will then check the workflow and see if a) is it in a suspend state and b) if yes, is the suspend sate waiting for the action (that was performed) to be performed. If yes to both it will resume that workflow, if no then it will keep it suspended. Let's have some examples, to make it a bit more clear. Request 1 has a workflow A that is configured to raise a (linked) request 2 that has a workflow B. Then in workflow A you set a "Suspend Wait For Resolution" and set the request ID input param to use the variable that has the value for request 2. When request 1 is raised, it spawns workflow A which will the progress, raising request 2 that spawns workflow B. Workflow 1 then suspends waiting for a resolution having request ID param for request 2. At this point you navigate to request 2 and resolve it. Here is where things might not proceed as you would think and I will refer to the underlined statement above. So, when request 2 is resolved, part of this action is invoking "processResume". This API will get the data based on the request from where the resolve action was performed which is request 2. This request has workflow B. The "processResume" will then open workflow B and checks the a) and b) above... You can see now that when the resolve action was performed on request 2 there was no action on workflow A which is the one we would have expected or wanted to resume... makes sense? So in order to resume workflow A you would need an action on request 1 - which will have a "processResume". So even if you have "Suspend Wait For Resolution" (in workflow A/request 1) with request ID input param as request 2, you still need an action on request 1 to trigger "processResume" for workflow A... Now, the above is from what I remember of how this suspend/resume was designed, might have changed although I did not see any code changes to suggest that... so worth a test but if it does not work as you would think it would even with the request ID param set for the linked request, the above is why... However...however... having an automated node that will action on a different request (by using a different value for the request ID param) does for for other types of automation...for example you can use a "Update Request" having another value for request ID param which will update this other request... but this logic does not apply to suspend/resume nodes due to how resuming triggers and executes as described above...