Victor
-
Posts
5,680 -
Joined
-
Last visited
-
Days Won
168
Content Type
Profiles
Forums
Enhancement Requests
Everything posted by Victor
-
 @Stefania Tarantino running workflows(*) will be displayed in this list, which is the intended purpose here. This allows any Hornbill administrator to review running workflows or failed ones for example to identify issues, potential gaps, blockers, etc for any workflow configuration. We would not want to empty this list, if we do that, Hornbill admins or BP designers will have no access to running workflows and in your case, you will not be able to access any (old) suspended workflow to identify why they are suspended and correct and optimised this in future configurations. Why would you say it would be a good practice to empty this list? I am trying to understand this because emptying this list as the term implies, would only remove them from view, any problematic workflow will still exist in an instance but now you will not know about nor you will have access to it. *we define a running workflow as any workflow that is not completed, failed or cancelled (this means a suspended workflow is a running workflow aka not completed)
@Stefania Tarantino running workflows(*) will be displayed in this list, which is the intended purpose here. This allows any Hornbill administrator to review running workflows or failed ones for example to identify issues, potential gaps, blockers, etc for any workflow configuration. We would not want to empty this list, if we do that, Hornbill admins or BP designers will have no access to running workflows and in your case, you will not be able to access any (old) suspended workflow to identify why they are suspended and correct and optimised this in future configurations. Why would you say it would be a good practice to empty this list? I am trying to understand this because emptying this list as the term implies, would only remove them from view, any problematic workflow will still exist in an instance but now you will not know about nor you will have access to it. *we define a running workflow as any workflow that is not completed, failed or cancelled (this means a suspended workflow is a running workflow aka not completed) -
@Stefania Tarantino I understand, but I don't see how the product has caused extra work? The workflows have been configured to be suspended indefinitely and they have, I don't see any fault here... Sorry, I am not sure what you mean here... workflows left where? You can reach out to customer success, I am certain they can arrange a session with our product specialists to review your current configuration and problematic areas that you noticed.
-
Closing Activities on Reassigned Requests
Victor replied to AlexOnTheHill's topic in Service Manager
@QEHNick rights are only visible on roles... you can think of roles as a collection of rights... so, for example, Incident Management Full Access
-
@Stefania Tarantino I think the keyword here is can... the request and workflow can (and at many staged they do) work independently. Obviously this does not mean that a request and it's associated workflow are completely independent... only means that they can be, or better said can perform actions independently, at various points in their lifetimes. I'll try and make this more clear with two examples: First example: we have, let's say, a very simple basic scenario. An alert email creates a request. This request will always be assigned to team A user X, will have the category NNN and will email user or contact Y something. Nothing more, this how that particular service desk operates for this scenario. Here, you can have the workflow automate some actions so user X does not have to perform them manually. The workflow here will initiate at the same time as the request (this is always like this). The workflow then will assign the request, set the category and send the email and then it will end (complete). All this time the workflow performed these actions there was no manual action on the request. There wasn't any analyst to perform an update, set a priority or otherwise action on that request in any shape or form. You might also notice in this scenario that once the workflow completes, the request is very much active. It's still in a "new" state, still appears in user X queue. At this point user X can perform other actions on the request, for example, set a priority, send another email to a possible interested party. Can resolve and close the request. All these actions performed by user X happened outside the workflow, they happened while the workflow was completed thus having no influence in any shape or form on the request. From all this perspective we can say that the workflow acted independently from the request (when it assigned categorised and emailed) and the request acted independently from the workflow (when it was prioritised resolved and closed). Second example: we now have a more common scenario, which is a, let's say, "classic" auto closure sequence. You have a request with an associated workflow. Upon closing the request, the service desk will wait for customer feedback for 2 working days. If the customer feedback is received within the timeframe, depending on the feedback the request reopened. If no feedback is received after 2 days, an email is sent to customer as a reminder for feedback then the service desk will wait for customer feedback for another 2 working days. If the customer feedback is received within the new timeframe, depending on the feedback the request can be reopened. If no feedback is received after these other 2 days, no further actions are taken. Here you can have the workflow automate this sequence so the user/analyst does not have to specifically monitor, chase and progress the respective request based on the feedback. Initially, in the early stages, you can have the request and workflow doing a number of things. And then, upon closure (when the request is closed) you can have the workflow perform the auto-closure sequence (wait for feedback - with expiry perhaps, when not ok feedback is received, reopen the request, when feedback expired, send email reminder and repeat from wait for feedback). You can see here that once the request is closed, the workflow is very much active and will perform a number of things. The analyst does not interact with the request anymore (unless is reopened) and assuming that ok feedback is received or no feedback is received, the workflow will wait and chase completely independent from the request, there is no other activity on this request since closure. I hope this clarifies a bit in what way and how requests and workflow can (and many times will) perform actions independently. In most scenarios, the request and it's workflow have many touching points, they often interact with each other and, if one desires, they can be configured to work and behave in perfect sync, although this is not really practical and not the true purpose of a business process. I would like to know more in what way the suspend nodes are causing you extra work? Can you detail on this please? Max loop count is a mechanism when you have a loop set in your workflow. Loops work with decision nodes where you have a decision branch connecting to a node prior to the decision. An example of a loop would be in the auto-closure sequence I described above where after the email reminder the workflow "loops back" to waiting for customer feedback. Max loop count specifies how many times a workflow can loop in a sequence, which is 1000. Suspend nodes don't work with loops, there is no loop mechanism here, they are event based. This is where an even triggers an action, for the category example, the event/trigger is the analyst setting the category which resumes the workflow or the event/trigger can be the node expiry (if configured) which also would resume the workflow.
-
@Stefania Tarantino There are ways to achieve this but I need to clarify that there is no specific built-in functionality to prevent closing a request without a category. Another thing to clarify is that workflows are requests are two independent entities that can do things and progress independently of each other. They can of course interact and they can be designed to interact but in essence, they are separate entities with their own paths and lifetimes. This means that, for example, a request can be manually closed by an analyst while the workflow does something completely different or simply is suspended at some point that has nothing to do with a request closure. This is an important aspect to keep in mind when designing workflows. If you want (to enforce) the category to be set on a request before is closed, one approach is locking actions. You can have the workflow lock the Resolve action and unlock it once the category has been provided. As you noticed, there are SM roles that can override the lock so analysts need to have the appropriate roles and rights for this to work. Also, you would need to ensure the request cannot be closed by another means, such as auto tasks which can run from custom buttons. If you have all the right configs in place, then this might be an issue that we should investigate, so if that's the case raise a support request with us. What about the "max count loop"? This has nothing to do with suspend nodes so I wanted to clarify this as well, if needed.
-
@billster there are two set of rules that would need to be configured here; one set to determine what SLA (Service Level Agreement) will be set on the request - these are the rules configured when you associate (corporate or service) SLAs to a service one set to determine what SL (Service Level) will be set on the request for the above SLA - these are the rules configured when you design the SLA on the SLA itself Perhaps there is a misconfiguration between the two or one set is done but not the other?
-
@Stefania Tarantino Does this mean that in your view, the Wait For Category node does not work as expected? What is your expectation in regards to this node? What would be the problem? Is that the workflows should have progressed to completion? If yes, then this is what @Steve Giller advised above, the workflow will suspend until the category is set on the request. If the node is not set with an expiry period then it will wait indefinitely, until the category is set. As to if the node should be configured with an expiry, it entirely depends on how you want/need it to work... if it should not wait indefinitely then set up an expiry that will progress the workflow automatically when the threshold is reached. As per above, the workflow will be suspended at this node indefinitely. Only setting the category will resume the workflow, no other action will do this. What is your understanding of "max count loop"? I think there is some confusion here in regards to "max count loop" and the suspend node...
-
@Berto2002 not quite, I'm afraid. There is a recalculation but it does not nullify anything like start and end of response timers. This is a case of APIs that need to execute in a specific sequence, will sometime queue up in a slightly different order, which is sufficient to lead to issues like timers not being marked or incorrect timer values.
-
Closing Activities on Reassigned Requests
Victor replied to AlexOnTheHill's topic in Service Manager
I know this is not answering the question about roles and such but Isn't this more of a problem whereby Team A assigns the request before completing a task assigned to the team? Why is the task not completed before reassigning? There could be a very valid reason here, I am just trying to see what that is... -
There are two type of subscriptions in Hornbill, platform subscriptions and application subscriptions. The full users you are referring too are platform users. In order for any of these users to have access to application functionality (e.g. Service Manager app) they need an application subscription (e.g. Service Manager subscription). Not all users need an application subscription only the ones that need to use application functionality. Users that appear in the list in Service Manager section (screenshot) are users that have been allocated an application subscription (Service Manager). If you remove a user from this list, the application subscription assigned to that user and it will also un-assign all the application roles the user has allocated. So any app user is a full user but, not all full users are also app users (meaning some full users are not app users).
-
How do I stop analysts/customers re-opening closed requests?
Victor replied to Estie's topic in Service Manager
Custom roles. -
You can drop the second Team criterion here... if the Team is "US 1st Line Support" then at this point it is certain it is not something else (e.g. 1st Line Support). So the second Team criterion is superfluous.
-
@Will J Douglas known issue I'm afraid, is being worked on.
-
@Stefania Tarantino may I ask why you need to have an exported list of these? The report provided by @James Ainsworth is quite all right however, I see it does query BP instances table which is a table that is not quite designed for reporting... in addition this is one of the most heavily used tables in HB so some care should be taken when used outside it's purpose...
-
This should now be fixed on all affected instances.
-
Yes, fix in progress... we will have all affected instances sorted shortly.
-
bug? Characters <&> Sent in Email Not Showing Correctly in the Timeline
Victor replied to AlexOnTheHill's topic in Service Manager
@JanS2000 yes the > is the formatting for > ... So what I would say you need there is like this (so dash and >) You can have just the ">" but what you would have had (if it wasn't for the formatting) would have been "->" so, it depends on how you want to separate categories with just ">" or "->"
-
bug? Characters <&> Sent in Email Not Showing Correctly in the Timeline
Victor replied to AlexOnTheHill's topic in Service Manager
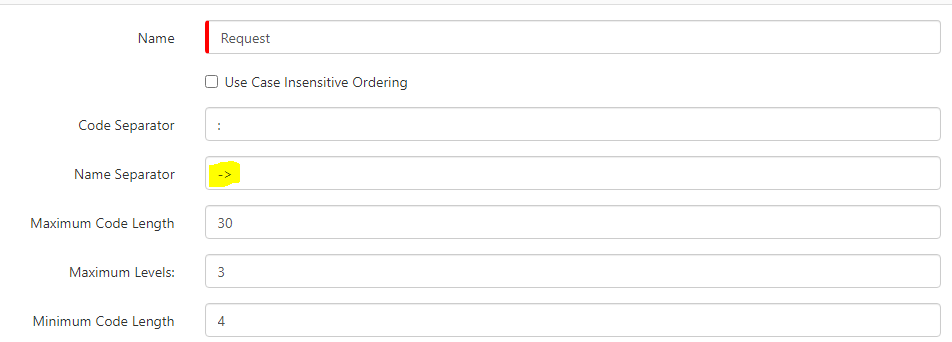
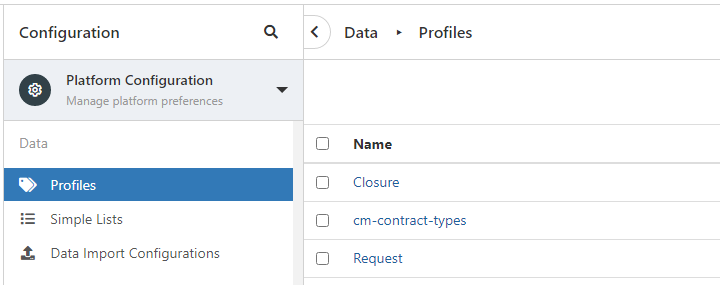
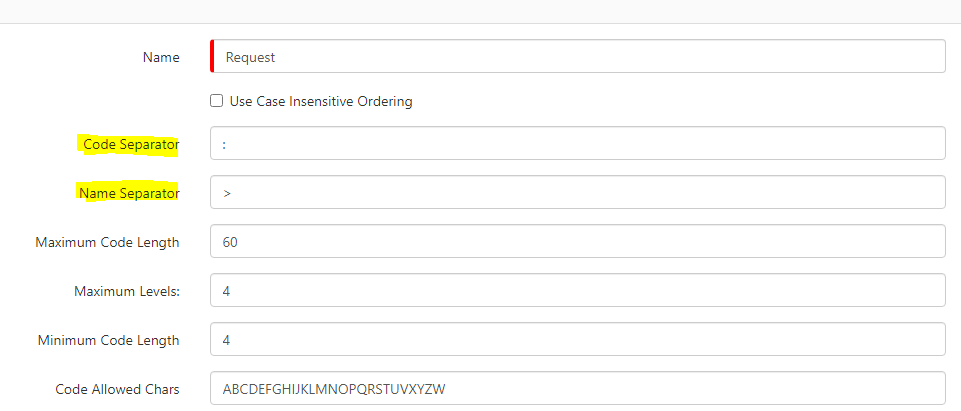
@JanS2000 it would be the Profiles in admin console: And in here, you would navigate to Requests. In here it could be Name or Code Separator that might have an incorrect value:
-
Email Response - Resulting in taking ticket off-hold
Victor replied to Salma Sarwar's topic in Service Manager
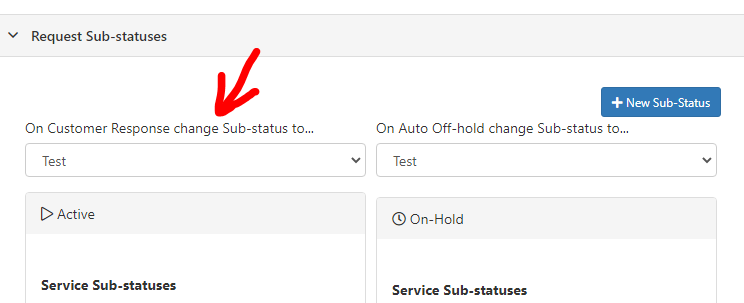
@Salma Sarwar you don't... the sub-status does that for you, no need to have the BP doing this... the email update is considered a "customer response"...
-
bug? Characters <&> Sent in Email Not Showing Correctly in the Timeline
Victor replied to AlexOnTheHill's topic in Service Manager
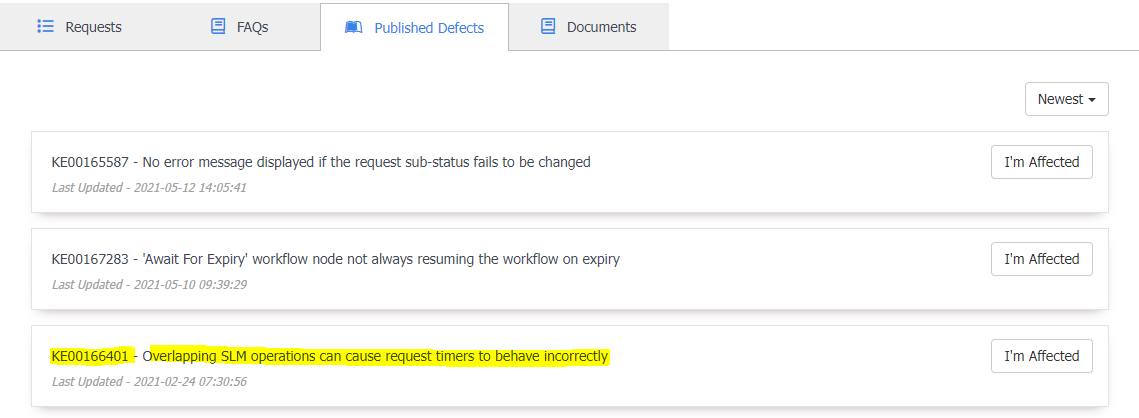
@AlexOnTheHill @Martyn Houghton @HHH @Jeremy development is now working on a fix for this defect. If you like to be notified when the fix is deployed please navigate to our customer success portal in Hornbill Support Service on Published Defects tab. Hit the "Me Too" button on the defect and you will be added as an impacted connection to it. Reference: KE00174669 @JanS2000 for the "category" timeline entry you have posted, have a look in categories configuration, it might be that it has an incorrect delimiter set up there. -
@HHH Super User role... but I don't think you want anyone to have this role just for editing other people timelines...
- 1 reply
-
- 1
-

-
Create Service Requests Automatically
Victor replied to MichaelB's topic in Integration Connectors, API & Webhooks
@MichaelB more of a query for integrations/API. I have moved the thread there. This might help: -
@Salma Sarwar I am not sure you need the same thing that @James Ainsworth was referring to... The idea of this post was that Will wanted to suspend a process waiting for a request update OR a request update from email (so one or the other). His thought was that it could be done using parallel processing. However in current BP engine you cannot have (any) suspend nodes (except human tasks) inside a parallel processing sequence. This (suspend nodes in parallel sequence) is being considered for the next iteration (version) of BP engine. As for take a request off hold when an email update is received, you can achieve this with request sub-statuses as I mentioned on your other post here:
-
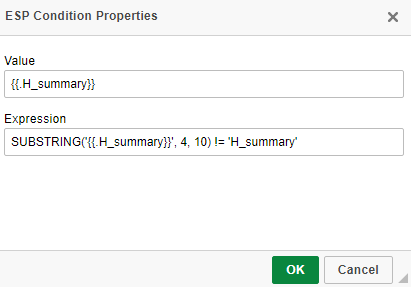
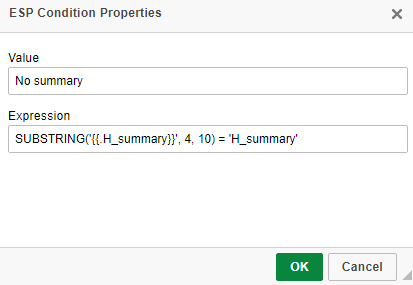
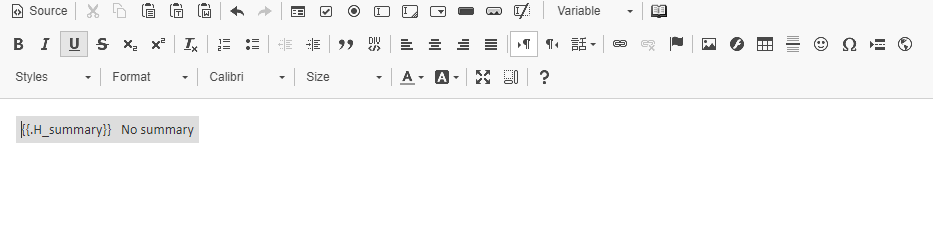
@Stefania Tarantino the expression above is a standard SUBSTRING expression use in SQL syntaxes. What it means is that it will check for the value of the variable to not be its syntax. Is just one way of doing this, I have included another option further below. But you cannot use the empty modifier on ESP conditions, the variable itself in the condition will never be empty, it will always have a value. The way the variables work in templates is they correspond to a table field. For example "{{.H_summary}}" variable corresponds to the request summary for the respective requests. The way the email template variable work is that if the request summary has a value in the database for that request, the variable will translate into the summary value. If the request summary does not have a value in the database, the variable will not translate into anything and it's value will be {{.H_summary}}. Therefore for the condition to check if the request summary has a value we need to make sure the variable value is not {{.H_summary}}. Another expression you can use there (instead of SUBSTRING) is: '{{.H_summary}}' NOT LIKE '%{.H_summary}}%' We need {{.H_summary}} on the left so the engine reads the value as a variable so it translates as described above and we need the %{.H_summary}}% in the right so the engine does not read the value as a variable that it needs to translate. EDIT: to clarify, we don't specifically need %{.H_summary}}% in the right or the "NOT LIKE" or the "SUBSTRING" expressions. We would need anything or something that would make the expression validate if the value is or isn't {{.H_summary}} (depending if the expression needs to check for a value in the correspondent table record or not - meaning an empty value in the correspondent table record). The above are just two suggestions that achieve this.
-
@Stefania Tarantino You need to chain 2 conditions: 1. For the summary having content and the ESP condition would be: I wrote the condition here for better visibility SUBSTRING('{{.H_summary}}', 4, 10) != 'H_summary' 2. For the summary not having content and the ESP condition would be: I wrote the condition here for better visibility: SUBSTRING('{{.H_summary}}', 4, 10) = 'H_summary' This is how it would look in the template, even if they look like one block, there are 2 separate conditions there: The template source would be something like this (so it shows there are 2 conditions there): Also this is a similar discussion: