Victor
-
Posts
5,680 -
Joined
-
Last visited
-
Days Won
168
5 Followers
.thumb.jpg.d5d3a83b710c9f83c4e4e8cccaba3f81.jpg)

Recent Profile Visitors
6,118 profile views






Victor's Achievements
")





-
 Hi All, At Hornbill, we strive to provide timely and efficient support to all our customers through our Community Forums. We understand the importance of these forums as a valuable resource for our customers to seek assistance and share knowledge with one another. However, despite our best efforts, there may be instances where some forum posts may go unnoticed or unanswered. We want to assure our customers that our Community Forums are an integral part of our arsenal and we are constantly working towards improving our response times. However, due to the high volume of posts and the dynamic nature of our support system, we are unable to guarantee specific response times or provide service levels. To address this issue and prevent any delays in receiving support, customers subscribed to an enhanced success plan (e.g. Premier Success) have the option to expedite an answer to an existing forum post by directly contacting our Hornbill Support Team through our website at https://www.hornbill.com/support/. By simply entering your details, you can also view your available support options and determine which Success Plan you are subscribed to. If you have any questions or require further clarification regarding our Success Plans. you can navigate to https://wiki.hornbill.com/index.php?title=Success_Plans, where you can find detailed information about our Success Plans and their respective benefits. We value the feedback and suggestions from our customers and we encourage them to continue utilizing our Community Forums as a platform to engage with us and other users. We thank our customers for their continued support and we look forward to assisting them in any way we can.
Hi All, At Hornbill, we strive to provide timely and efficient support to all our customers through our Community Forums. We understand the importance of these forums as a valuable resource for our customers to seek assistance and share knowledge with one another. However, despite our best efforts, there may be instances where some forum posts may go unnoticed or unanswered. We want to assure our customers that our Community Forums are an integral part of our arsenal and we are constantly working towards improving our response times. However, due to the high volume of posts and the dynamic nature of our support system, we are unable to guarantee specific response times or provide service levels. To address this issue and prevent any delays in receiving support, customers subscribed to an enhanced success plan (e.g. Premier Success) have the option to expedite an answer to an existing forum post by directly contacting our Hornbill Support Team through our website at https://www.hornbill.com/support/. By simply entering your details, you can also view your available support options and determine which Success Plan you are subscribed to. If you have any questions or require further clarification regarding our Success Plans. you can navigate to https://wiki.hornbill.com/index.php?title=Success_Plans, where you can find detailed information about our Success Plans and their respective benefits. We value the feedback and suggestions from our customers and we encourage them to continue utilizing our Community Forums as a platform to engage with us and other users. We thank our customers for their continued support and we look forward to assisting them in any way we can. -
@katy_palmer happy to hear what is this extremely sensitive reason (you can send me a private message here if you like). More often than not the solution to the issue you are trying to address here can be solved by other means, and not by having user IDs changed.
-
loginID not containing a value from a Get Customer Node
Victor replied to Fizza's topic in Service Manager
@Fizza Before any further discussion, we need to have a more clear understanding of the terms "Customer" and "Logon ID". When referring to the customer, it is important to specify whether this pertains to the customer of the request at hand. Furthermore, we need to determine if this customer is an external user, such as a contact, or an internal user, such as a basic or full user. This distinction is essential in order to accurately assess the situation and provide appropriate solutions. -
Unable to see the email template?
Victor replied to Adrian Simpkins's topic in System Administration
When you get the first "broken template" displayed, F5 to refresh the page. This will then display the "whole template". And also, you can then edit any other template, without encountering this issue. This is being looked at by development. -
@Val C what exactly are you looking to get from this report?
-
Azure AD Import - Removing the use of Proxy
Victor replied to JamesGreen's topic in Integration Connectors, API & Webhooks
@JamesGreen ok... as mentioned above the tool does not have anything "built-in" to route connections through proxies it simply uses the connection as provided by the environment where it runs... so I would say something in your environment has the connection routed through the proxy... maybe the machine itself needs to be restarted after the changes, not sure... but not my area of expertise I'm afraid.. -
Just FYI while in the pipeline, no one will be able to see it apart from the user designing the service, and only for the purpose of designing the service further until is ready to be included in the catalogue.
-
@Lee C you would do this in "Profiles" in the admin tool. This option is located in the "Data" section. https://docs.hornbill.com/esp-config/data/profiles
-
@Lee C https://docs.hornbill.com/servicemanager-config/customize/workflows/service-manager-workflows#email-notifications
-
Azure AD Import - Removing the use of Proxy
Victor replied to JamesGreen's topic in Integration Connectors, API & Webhooks
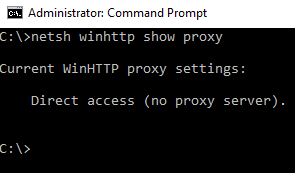
The tool does not have anything inherently built to use connections via proxy it simply uses the connection set in the environment... in cmd prompt window if you type in netsh winhttp show proxy what do you get? If the environment has no proxies configured it should show something like this: If the tool still tries to connect via proxies it is the connection in your environment still set to use proxies. Maybe the machine needs a restart once the proxy config is reset (removed). However, I am no expert in this area.
-
Backlog measure - Without Date ranging column
Victor replied to Andrei Spiridon's topic in Service Manager
@Andrei Spiridon would recommend using the option on your Premier Success plan and raise a support request. If this is a defect you will also be provided with a defect reference you can then track with our support team. -
As far as we know, it shouldn't. The issue should only be when editing workflow nodes. If you experience an issue with raising requests, I would advise raising it with support. The issue might be related to the one on workflow but might very well be something different that would need to be investigated separately.
-
A fix is being rolled out. ETA for fix deployment is currently 10 min.
-
@Jacopo Carraro we have moved this thread to the appropriate section but just an FYI reminder:
-
Amending font colour within Customer Portal
Victor replied to Liam Jackson's topic in Employee Portal
@Liam Jackson we have moved this thread to the appropriate section but just an FYI reminder: