Gerry
-
Posts
2,437 -
Joined
-
Last visited
-
Days Won
172
Content Type
Profiles
Forums
Enhancement Requests
Everything posted by Gerry
-
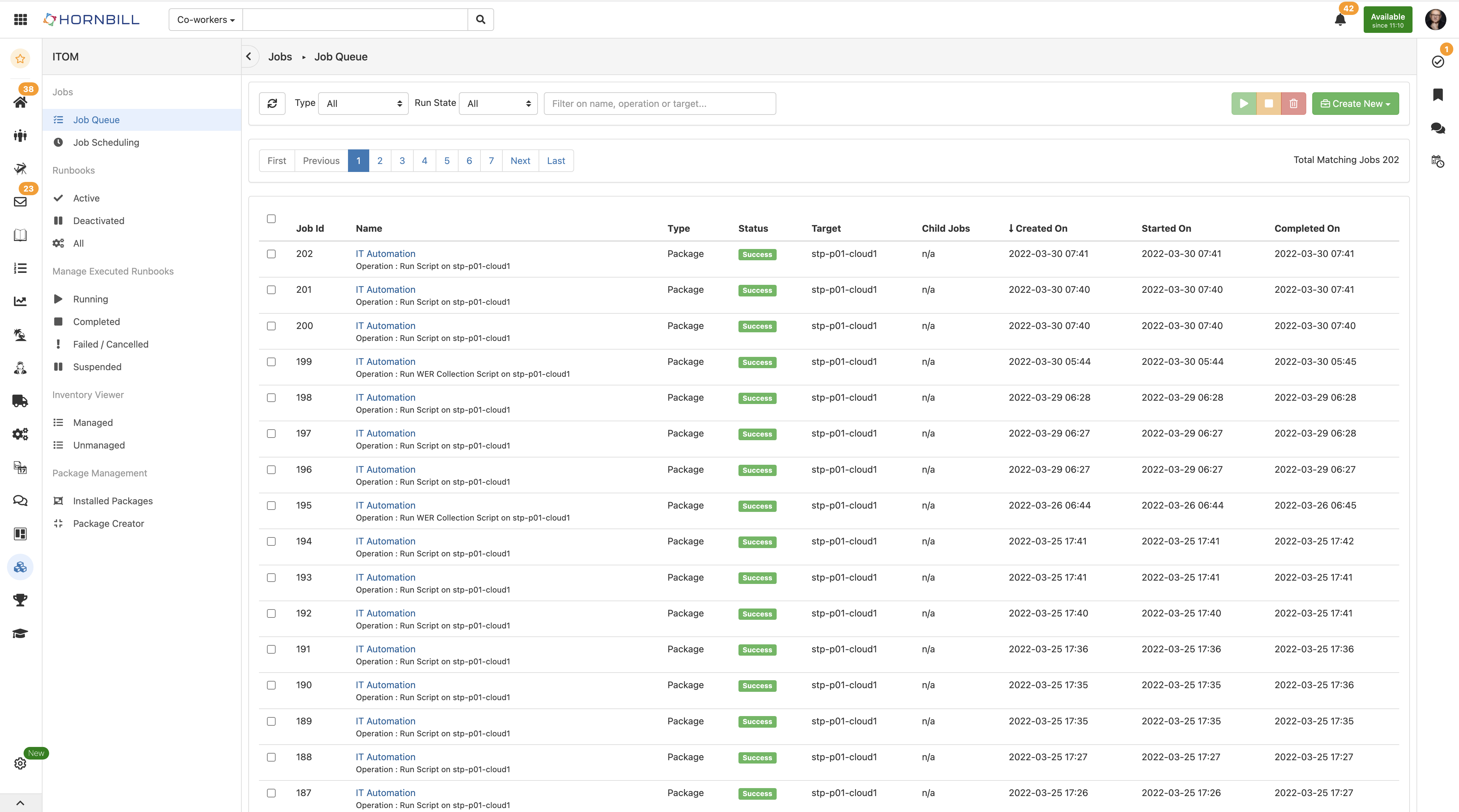
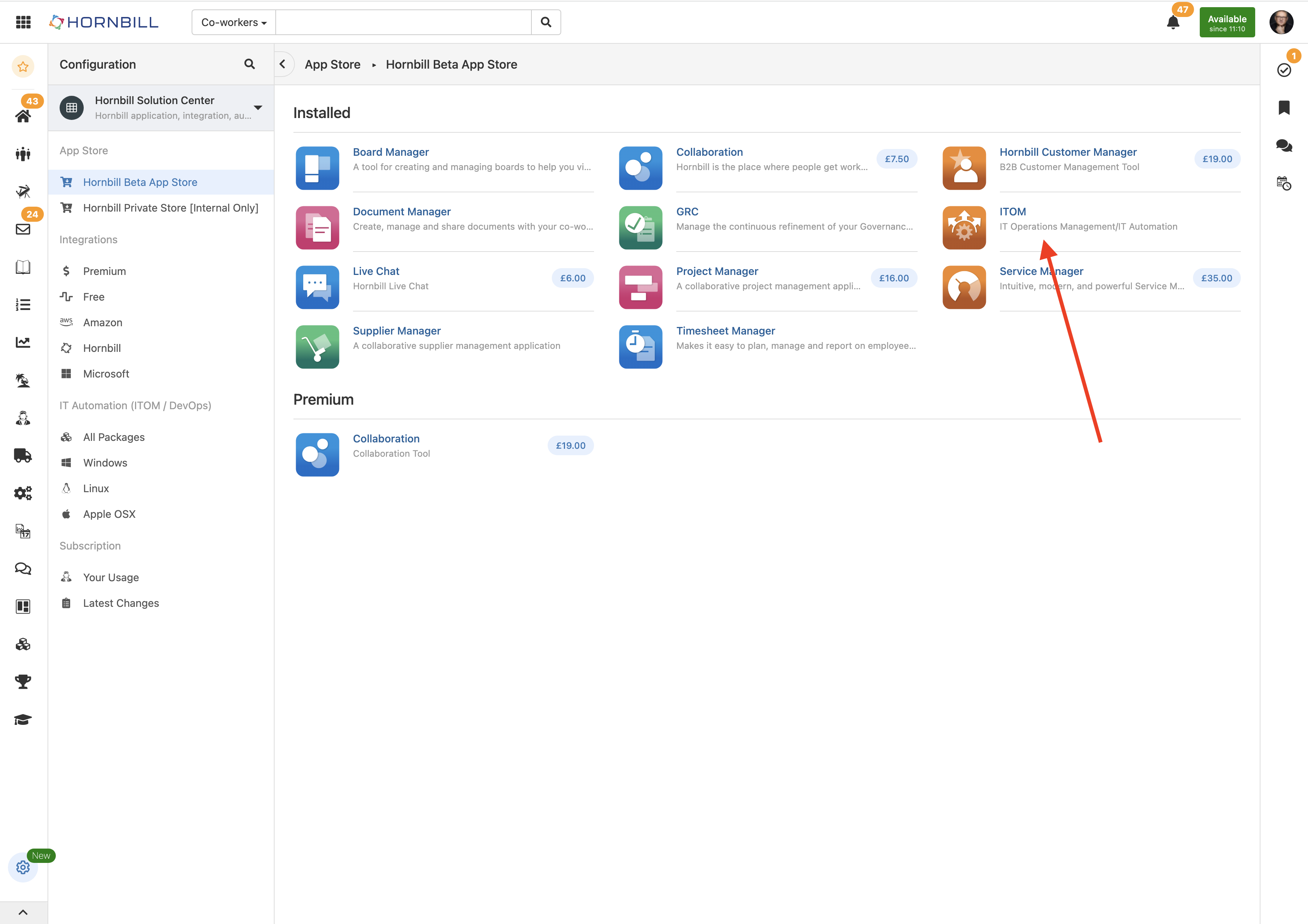
 I am please to let you know that the ITOM functionally originally built in the Admin tool has now been fully migrated to a new application which you can install from the App Store. Once you have installed the application the ITOM data is automatically migrated to the new application namespace and you will no longer be able to use the ITOM UI in the old admin interface. The application will be available on the App store in the next day or so, so if you have ITOM included in your subscription, or you want to try out ITOM with a use-restricted free tier, you can just install the application from the app store. NOTES ON INSTALLING ITOM APPLICATION When you install the ITOM application you will no longer be able to access the UI in the old Admin tool. However, your ITOM users will not see the new ITOM application in the icon bar until they have been granted rights to the ITOM application, this is the same as any other application you would install on Hornbill. So installing ITOM involves the following steps. Install the ITOM application from the App Store Switch to the administration of the newly installed ITOM application Select the "Roles" item in the left-hand navigation, you will note there are two ITOM roles application-defend, these are ITOM Application User and ITOM Application Administrator, for each role, assign your users as required. Let your ITOM users know they will need to logout and back in again, at which point they will see the new ITOM application icon The user interface, while restyled is essentially the same as what was present before so there should be no problem transitioning from the current UI to the new UI for your ITOM users
I am please to let you know that the ITOM functionally originally built in the Admin tool has now been fully migrated to a new application which you can install from the App Store. Once you have installed the application the ITOM data is automatically migrated to the new application namespace and you will no longer be able to use the ITOM UI in the old admin interface. The application will be available on the App store in the next day or so, so if you have ITOM included in your subscription, or you want to try out ITOM with a use-restricted free tier, you can just install the application from the app store. NOTES ON INSTALLING ITOM APPLICATION When you install the ITOM application you will no longer be able to access the UI in the old Admin tool. However, your ITOM users will not see the new ITOM application in the icon bar until they have been granted rights to the ITOM application, this is the same as any other application you would install on Hornbill. So installing ITOM involves the following steps. Install the ITOM application from the App Store Switch to the administration of the newly installed ITOM application Select the "Roles" item in the left-hand navigation, you will note there are two ITOM roles application-defend, these are ITOM Application User and ITOM Application Administrator, for each role, assign your users as required. Let your ITOM users know they will need to logout and back in again, at which point they will see the new ITOM application icon The user interface, while restyled is essentially the same as what was present before so there should be no problem transitioning from the current UI to the new UI for your ITOM users
-
@will.good It has always done this to the best of my knowledge, the Hornbill logo is supposed to go back to the website in both cases, not sure why they behave differently, I will ask someone to take a look Gerry
-
KnowledgeBase Questions from Product Roadmap Update
Gerry replied to Gerry's topic in Service Manager
@samwoo "I am very much looking forward to the improvements you and the rest of Hornbill are bringing to the table, keep up the excellent work!" thank you, I am very happy to be called back to this subject if what we deliver is not up to the promises I have made above. We have a lot to do but we also have a lot being worked on, so there should be q few incremental improvements made available along the way too. I will probably turn the above diatribe into a blog article at some point Gerry -
KnowledgeBase Questions from Product Roadmap Update
Gerry replied to Gerry's topic in Service Manager
@samwoo Ok so you are going to love my rather "unexciting" view on this subject... "The AI would use actual knowledge in the system and build upon that. The AI would be able to enhance user experience and provide the right guidance to the right people with machine-learning." that is basically an index. Think about what an index is... every time you create a piece of relevant information it is indexed, that could be said that "the machine has learned that new piece of information", such that the next time you look for that thing or something like that the machine (your index) will know about that and will return you that information, with some form of relevance in relation to either the thing you searched for, or, the other things that were also returned. "I am going to admit that I don't have a great understanding of how AI works" you are not alone here, AI has been so over-hyped in the market that you think its some magic, but its really not. There are companies, even in our very own service management tooling space that literally include AI in their product name, why, because it sells... its the sexy new thing that companies invest in. I have seen so many products essentially call their indexing or their ProCap equivalent or even their business process tools that can make decisions based on user input - "AI", but its not, at least not what my understanding of AI is. There is far too much to say on this subject to cover AI as a topic in this post, but I would say this. I believe that everything you have suggested in your post above we will achieve, the system will help users get to the right service, and provide the most relevant answers, and may even lead to a self-resolution outcome, this will require quite a lot of up-front work for customers to set up properly , but once set up it will appear like magic. If we archived that, and then called it "AI" would you consider that requirement met? Going back to your statement "I am going to admit that I don't have a great understanding of how AI works". if we make something that looks like it works well, and we call it "AI" even though under the hood there is no "AI Technologies" at play, would that be good enough? would you just take our word for it that there as "AI" involved, or would you go and learn enough about AI technologies to refute our claim about "AI" if the solution we said was AI did not work too well? Here is the thing, I am, very much to my own detriment, "honest" and I do have a basic grasp of how AI/ML works and how it can be applied, and for me to take something that "looks like AI" and call it "AI" when I know deep down, its does not meet that criteria, I just can't bring myself to do it, I simply can't be dishonest like that, I do not want to mislead people, or make claims that are not true, or indeed take advantage of people who, like yourself, "admit that I don't have a great understanding of how AI works" which means we don't get to sell fantasies or tick the AI box because my own personal pride and professionalism gets in the way. Now do not get me wrong here, I am not saying AI is not a real thing, it is, and there are some really extraordinary use-cases for AI/ML in use today, but they are very limited in their scope, its best said like this... AI is not a general technology that applies to any software and any situation to make it better, rather,AI/ML is a general set of computing ideas that have very specific applications, that applied right can be infinitely more effective than a human intelligence. The general principle of AI/ML is this. You feed the learning model known good, tagged, data, that in the data sample has a high degree of repetition of characteristics that can be classified. For example, in image recognition, you feed in images, let's say of animals, into the model, telling the model what each animal is, each time it gets a new image, the model does its adjustments looking for best accuracy of results. After a decent enough sample of tagged data, the model is now able to recognise animals in other images that it has not previously seen in the training phase, "with some degree of statistical accuracy". The output is a statistical likelihood of the image being a cat or a dog etc but its not 100% precise... thats a textbook example of AI that is one of the earliest use cases. Refinements on this might be multiple models, say for facial recognition, where the first model might generally identify characteristics of a face, for example, gender, race, hair style/type, eye colour and many other generally identifiable, then using those identified characteristics, a second model might be used to take a much smaller subset of individuals from a national database to try and identify the individual person. Yet another example is, cancer screening, feed an ML model with tagged images of chest x-rays for all patients over the last 20 years that were screened for lung cancer, telling the model which ones had a positive and negative diagnosis, once the model has seen enough data, you can now feed in new x-ray images and the model can help screen and identify potential positive diagnosis. This is a great example that is used in real life today and it works, it saves lives for sure, but its not foolproof and there is probably at least 20 years to trials now to see if, and I know that this sounds harsh, but to see if the false negatives are a low enough percentage to be acceptable, but until then, while the ML models are getting it right 80-90% of the time, thats well below the threshold of it being an *alternative* to a qualified medical expert looking at each x-ray. Of course people also makes mistakes, so its reasonable to think that this technology should get good enough to be on average, better at diagnosing this kind of thing than the human equivalent. There are so many other AI use cases, but they all fit this pattern, speech recognition, image recognition, big data pattern recognition is large scale retail/consumer information, moving image recognition and many related technologies around joining the dots between expected and differences, for example, moving vehicles on roads in self-drive and driving assistance systems. So back to your typical service desk environment, its much harder to find a use-case that will actually make a material difference, and that is certainly true in relation to the cost of truly realising AI. I don't know of any servicedesk deployments that I have ever seen that have anything like the amounts of relevant long-lived data needed to train a model with anything meaningful, and, in IT especially, things change so very quickly, stuff thats relevant today will not be relevant in 12 months time. Think about it like this, if you wanted to train a model on Windows 10 errors and make it really smart so customers could help themselves, you could do that, but by the time you have collected enough data, trained the model and deployed into use, its likely that Windows 11 will already be replacing Windows 10, but in my example above, screening for lung cancer for example, those x-ray images and the characteristics that identify lung cancer will only change over many 100's of years, so the ML model has time and enough data to learn from and get better, it will not suddenly be the case that everyone now has Lungs 2.0 that are fundamentally different to Lungs 1.0. The bottom line is, for most companies "peddling" AI, it is more marketing than it is of real value for most use cases. There is a lot of snake-oil selling of stuff with the "AI" badge precisely because buyers are "going to admit that I don't have a great understanding of how AI works", and are going to buy into the idea of AI because it looks good, so, if they see something that looks like AI because it works well, and its called AI, then to them its of course it is AI... but for me thats really dishonest marketing and not something I have ever been able to bring myself or Hornbill to do. Of course that does mean that when we get those tender documents and they say "you mush have AI" we generally say no here.. so there is continued commercial pressure on us to play the same marketing gams around AI ... sadly... and that can cost us customers, but for me, our professional integrity is more important. Gerry -
KnowledgeBase Questions from Product Roadmap Update
Gerry replied to Gerry's topic in Service Manager
@Stephen.whittle I want to try and avoid calling it "the knowledge base" as if its a new icon or something like that. The work around knowledge is all to do with creating a much better experience and integration of knowledge during the call logging and analyst support workflows, a very big part of which will be better access to knowledge, with actionable outcomes, better, more contextual search and so on. The foundational work around this is already underway and so you will start to see evolutionary improvements in FAQs for example in the coming weeks, with a bigger foundation of other changes following that. Timescales are variable of course because we have many commitments and much to do, but broadly in line what I had set out in the three step plan, the first of which (the admin stuff, the new ITOM app) are complete now, we are currently working on some deliverable improvements around FAQ's and have just started the next major Stage 2 work around the service portfolio/catalog/request configuration changes, this is going to be a big change, a lot of work and possibly some breaking changes we will have to manage along the way too. This work in the portfolio gives is a solid foundation to get to the final stage which is the portals, the employee and customer experiences, data models and of course that all important knowledge integration with these processes. So work in progress, lots to and you will see various incremental improvements along the way during Q2 and Q3. Gerry -
@Darren Rose "the last login to Project Manager" a user does not log into an app, what happens is a user gets access to an app based on the roles and rights assigned. The only way you can achieve what you are asking is to look at all the user accounts who have PM assigned to them, and see when the last time they logged into Hornbill was. Gerry
-
@Martyn Houghton "The Widgets do not give you the option to rename them either" Thats exactly right. When I look at what you are asking for, you appear to be asking for one thing but trying to solve another (or both) things along the way. From a design point of view, the measures can be thought of as named data sources, and in themselves they have no notion of presentation. The measure(s) are generally presented in widgets, so from a design point of view the correct place to add this would be to add an option to set the display name of the measure at the point of including it in the widget, that way the title being used for the measure is defined in the configuration of the widget, and not the measure its self. However, there appears to be a secondary problem that you are also trying to indirectly solve, that is, you have what seems to be a very large number of measures, you have, because of this, opted to adopt a naming convention to help you organise the measures, which mean you can no longer use the measures own name for display purposes - is that fair? The system where you define/manage measures was never really intended to have such a large list of 1400+ items, I am actually surprised anyone would have that many, I am not surprised the the system can operate with such a large number, but from a management perspective I can see why that is so difficult to maintain. This though is a problem that is distinctly separate from the problem of the display name of measures. I assume though that its the display name that is the priority here? I am going to have someone look at the possibility of extending the widget config to optionally include a display name for each measure added to that widget. Gerry
-
@Martyn Houghton This is being discussed, but from what I can see from your comments, the "Display Name" of a measure which is presented on a Widget should be a property of the widget and not the measure it self, that would make more sense give that "the measure" is a data source whereas the "widget" is the presentation of that data? Does that make sense? Gerry
-
ESP (3582) update - user accounts where Login ID is different to UserID
Gerry replied to nasimg's topic in Service Manager
@nasimg The essence of the change was relating to multi-login being allowed when the login ID was different to the user ID, this was unintentional and led to lots of open ended, inactive sessions that could build on larger systems. When a basic user login happens, previous sessions for that basic user are closed, this is how its worked previously but not in the case when the login ID was different to the User ID as it turns out. So that is what has been fixed. Gerry -
As part of the process of simplifying the administration of Hornbill, we have now completely removed the need for you to have to manage "database table" rights. Instead we take care of this under the hood based on system and application rights that are applied. This will be rolled out over the coming days. A simple change that will make setting up security roles in Hornbill a lot simpler. Gerry
-
Extract info from a reply to a ticket (Business Process)
Gerry replied to RIchard Horton's topic in Service Manager
Hi Richard, I am not really sure I understand how you envisage this would work. I am assuming you are talking about the email auto responder and the BPM acting on the email received. So assume you have a ticket logged, a business process was started, and has acted on that piece of data, and the workflow is now sitting at some arbitrary point. A new email from that supplier comes in with such a watermark... what (would you like to) happens next? Gerry -
@Michael Sharp As far as I understand it, If **REDACTED** is your domain, this is something you would need to do on the DNS servers that host your domain. The hornbill platform makes it possible for your instance to be configured in relation to email to be DMARC compliant because we support both DKIM and SPF, but our own email, that is emails that come from Hornbill.com for example, to the best of my knowledge is not specifically DMARC authorized, although we do use both DKIM and SPF Gerry
-
I am delighted to be able to say that the new global search rollout is now complete for all production instances. As well as being a significant improvement over the prior search capability, we are really only scratching the surface of what this can be put to work to do, as such, this migration gives us a brand new, and very capable search capability which we will be taking advantage of over time. In the mean time, having had this in the works for well over 20 months, this is live and your global search results should be a lot better, be a lot faster and from our point of view, a lot easier to scale, maintain and build on. Over the next couple of months we will be monitoring, tuning, optimising and of course, ripping out all of the service, code and data that relates to the old, out of service search system, clearing a path to future evolution and improvements. Gerry
- 1 reply
-
- 1
-

-
Extract info from a reply to a ticket (Business Process)
Gerry replied to RIchard Horton's topic in Service Manager
@RIchard Horton An example of the watermark might be helpful here, it may be possible to extract it, it depends what it is, and where it is. Gerry -
@RIchard Horton When you say "extract their data" who's data are you talking about? the support technicians or the customers? In either case what is the purpose of the extraction. Hornbill is a system or record and as a general rule customers seem to want to keep all data forever. The problem with extraction is, the data around tickets is highly integrated with many other related data areas and while some data is denormalised, most is not, so an extract would from from a lot of different related data sources. The data is also NOT flat, its quiet hierarchical by nature, so extracting the data into what form? Can just put into a spreadsheet and as you have probably observed there are a lot of GUID's and other such non-people-friendly references and pointers. I am keen to understand the use case here, once the data has been extracted for a user/customer - what do you want to do with that data? Thanks Gerry
-
Latest update with reported issues resolved was pushed live on Sunday. Next up, for those of you using ITOM, the new ITOM application will be made available, I will post separately when thats available for you to install. Should be in the next week or so Gerry
-
SIS Communications Via Proxy is this now possible?
Gerry replied to Adam Toms's topic in IT Operations Management
@Adam Toms We don't currently support proxy comms because its very technically restrictive and could make our site integration services unreliable, difficult to support and possibly even inoperable because a proxy puts an arbiter between our service and our SIS server. Our SIS servers run behind you firewall, in your security domain and anything it can do *must* be done in the context of the security policies applied on your network and the account(s) you give the SIS server to work with. Everything the SIS server does, is logged, these logs are written to log files on your computer which means all activity the SIS server is told by your instructions via automation is subject to full audit by yourselves/your security teams. We have designed the SIS server implementation to be "trustworthy", but we cannot insist our customers trust us or it, we can only be transparent in the way it works, and, ensure that everything that it does is fully auditable. The data the goes between your instance on Hornbill and your SIS server(s) is encrypted using industry-strength TLS, and I am aware that security teams very much like to use proxies because a proxy allows the breaking of that encryption for man-in-the-middle data inspection, so I understand the reason for the question. Currently though, its not something we support. Gerry -
@derekgreen I wanted to post as I think this is an important point. We (being Hornbill) cannot generally help with customers own infrastructure deployed systems. Every customer has different setups and configurations, and while some of our people may well have some of this knowledge its not something we can officially support, or necessarily even provide advice on. On the Hornbill Platform we have made SSO using SAML 2.0 really simple to set up on our end to reduce the burden of knowhow normally placed on our customers, but there is considerable setup and knowledge required on any directory service deployment (ADFS in your case) which has to be set up correctly, and if you are being tasked with setting this up, whoever is responsible for your ADFS infrastructure internally need to be advising you/your team, if you /your team do not have the knowledge yourselves. There is a lot to go wrong here and you should be aware of this. I am sure there are people in this community (including individuals from Hornbill) who may well be able to offer guidance, but Hornbill is not in a position to *officially* support your internal systems, including your ADFS deployment. Gerry
-
In the next Hornbill update, there will be a more prominent and un-dismiss-able notice presented in the user application on the top navigation bar, this will be seen by any user that is still using IE11 to serve as a reminder that we are ending support for IE11. These is also a link in this notice that explains more about the change. I am told by our engineering team that in order to start to implement some of our backlog we need use some of the more modern browser features that are not supported in IE11 at all. So while we will not set out intentionally to stop IE11 working, its very likely that parts of Hornbill will become broken if you are using IE11, and when that does occur, we will have no possible way of fixing those problems as the breakages will be caused by using browser features which simply do not exist in IE11 Maintaining compatibility with IE11 has been one of the major contributing factors to our inability to effect change, we currently have quite a lot of "workarounds, polyfills and legacy code" just to keep IE11 working, by dropping support for IE11 we can immediately set to work in modernising these code areas and paving the way to make significant UI/UX improvements. We are doing our best to warn you in advance but this change is coming fast... You can see more about Microsoft ending IE11 support here: - https://docs.microsoft.com/en-us/lifecycle/announcements/internet-explorer-11-end-of-support Gerry
-
New Admin Tool - minor issue with selecting items on canvas
Gerry replied to Sam P's topic in Service Manager
@Sam P This was fixed a couple of days ago, along with a bunch of other stuff. This is on beta now and is scheduled for live push Friday AM. Gerry
-
@Martyn Houghton The admin search is the key to efficient power use, once you know the system and your standing data you can get to anything pretty much with just a few key presses. I would encourage you to use the search as your goto navigation, it tool me a while but now its almost my natural way to navigate the admin stuff. Gerry
-
@Martyn Houghton Thanks for the report, I am afraid this one escaped the net, basically we had a fractional version difference between the library (AngularJS) used in Admin and Core, the result was a few little things like this went unnoticed. Thats been rectified along with a bunch of other stuff and will be pushed to live Thursday. Our current cadence for Core UI releases is 72 hours (3 days) which ensures each release sits on our dev and beta streams for 24 and 48 hours respectively before being pushed to live. We will hotfix anything that is more urgent than that, but in the case of the new Admin UI we know that you have the old Admin UI to fall back on. Gerry
-
Should be available globally now. Enjoy...
-
https://death-to-ie11.com/ As you know, Microsoft has officially announced the end of support for IE11, they have introduced Edge as a replacement browser which is based on Google Chrome. In line with this change, Hornbill are looking to drop support from our development workflows for IE11 also. There is an ever growing list of improvements, enhancements and even defect fixes that are currently sitting in our backlog classified as "Can'd Do This Because of IE11", and just like previous Microsoft browsers our ability to maintain compatibility is both diminishing and becoming a very material progress constraint. Currently we have a friendly and dismissible warning in the UI that is reminding for users on IE11 that support is being dropped in line with Microsoft which is around the June 2022 timeframe. However, over the coming weeks we are going to be making that message more prominent and imposing. Statistically, less than 1% of our total network traffic is originating from IE11, coming from around 11 customer organisations, so the use is actually very small, none the less despite the warnings so far, that usage has not really changed. So starting with the release of the new Admin UI, future developments are very likely to simply not work in IE11 as we are not consoling the IE11 edge cases, or adding a bunch of polyfill's just to plug the gaps in IE, we are taking advantage of the better security and more modern functionality that the newer, more modern browsers bring to the table. Right now this only apply to the User app (live.hornbill.com) but will very soon also apply to the other portals too, but please be aware that this will all change during the course of H1/22 as our codebase transitions out of supporting the now ancient IE11 technology. If you have IE11 users accessing Hornbill, please do what you can to move them to a more modern alternative. Thanks, Gerry
-
I mentioned during the last product update meeting that we have been working on improving the global search capability. This is not an incremental improvement, this particular change is a complete ground-up reimplementation of our search infrastructure, everything from server clusters, application and search and security layers have all been completely re-worked. Our initial goal is to provide like-for-like function, which means as we roll out, you should not really notice any difference apart from: - * Global searches will (should in most cases anyway) provide you more relevant results, the underlying technology stack we are using is much more advanced than what we had in place before. * Global searches should be faster. * Global searches will be much less error prone (we had a lot of failures behind the scenes which made the search experience not as good as it should have been) We are currently in the rollout phase, some instances have already been rolled out, and we are doing more all of the time, this involves a lot of re-indexing of stuff, so it takes a while, another 4-6 weeks at least we predict when the whole customer estate will have been migrated. This change is a much bigger deal than is apparent in use, specifically though, this paves the way for much better and more unified search capabilities, which of course will be continuously rolled out and deployed. Gerry
- 1 reply
-
- 5
-