Gerry
-
Posts
2,437 -
Joined
-
Last visited
-
Days Won
172
Content Type
Profiles
Forums
Enhancement Requests
Everything posted by Gerry
-

Accessing Hornbill on your own Custom Domain
Gerry replied to Gerry's topic in System Administration
Hi Alex, To be honest we have not really made any further progress with this. The main complexities are around SSL certificate management and trust and more recently adding cloudflare to our stack makes this more complicated again as we have to either bypass that or find a way to work with Cloudflare and individual customers, or maybe bypass cloudflare for customers on a custom domain. We will continue to look at this but any service we offer around this will be a chargeable service and will not likely be low cost either. Gerry -
@m.vandun Another possibility would be to use rights to control mailbox access, I believe its possible to configure mailbox rights such that you can move a message to the Deleted Items (a soft delete) but you are not allowed to delete the message from the mailbox. Would that work? Gerry
-
@Martyn Houghton As above, check the allow multilogon setting. However, what you are doing now running a separate account is the correct approach for an unattended logged in session, at least it is if security is important. Gerry
-
@Lyonel Not sure why you are getting these timeouts, as a general rule things work better if the wallboards use a dedicated account. However, if multoLogon is disabled (this is a system setting you can change in the admin tool) then a user logging in using the same account will kill other sessions for that account. This is off by default. However, on some instances we have had to turn this on because a bad integration implementation (customer developed) was logging in, querying some data and not logging out, and that was happening once a second so the instance was slowing down as 10's of thousands of sessions were being created and not destroyed. We advised to not use the userLogon/userLogOff API's for integration a) because its very bad practice as it leads to passwords being hard coded into scripts and b ) because it was killing all of the instances allocated resources. The correct way to use the API's for integration is with the API keys scheme. So its worth checking your settings to see if multi logon is disabled, that would be a good start. I would also recommend you use a separate user account for you dashboards, if not for reliability for the sake of security. The count should have the minimum rights needed to display the dashboard and no more. Gerry
-
@m.vandun In your case, your instance was configured with allowMultiLogin disabled, this means if you log in as you a second time it will automatically kick any open sessions on your account. We have disabled this option for you so that should not happen any more. Gerry
-
HI Martyn, Yes some detail would appear to have been lost in the translation from the internal comms back to you, my apologies. I will try to make sure that in future we move these deeply technical types of conversations on the forums where the subject matter expert can communicate directly and at the right level of detail to avoid translation loss.. Back to the problem - when you receive such a message you will get the text part attached, you can also turn on message tracking and get the originating RFC822 message its self, in both of these you will see the illegal character streams. We have discussed internally introducing a system setting "hack switch" which when turned on would force our system to ignore the errors and replace all invalid characters with '?' or something like that. This way an individual customer could "switch on" the hack and get that behaviour, but on the understanding that it is in fact a hack and other character encoding/formatting issues might occur as a result. If you desperately need us to do this, let me know and I will see what we can do. Please let me know how you get on. Gerry
-
Hi Martyn, In answer to your specific question "I have asked for details of the character sets supported by the currently implemented component." we fully support Unicode, so all possible characters defined in the Unicode standard throughout the entire system - or at least that is our design intent (we as of the time of this writing, do have some unicode issues in WebDAV URL paths which we are working on resolving, bit nothing to do with email processing). If your problem is the second one above relating to invalid UTF-8 encoding, its not a question of character set support at all, the problem is, the mail message contains a mix of UTF-8 and something else (probably a Latin 1 type character set), so we are unable to process it, partly because its mixed and therefore invalid, and partly because there is no possible way to know what the character encoding is supposed to be. The other thing we do not support is UTF-7 obviously, which is an encoding scheme rather than a character set. Gerry
-
Hi Martyn, Ah, actually check back on the internal workspace, your error may be this one...please correct me if I am wrong... these posts are useful knowledge to share with our community so I thought it worth posting anyways. This is another oddity, and we have seen this a small number of times, here is a full explanation of the actual problem. SUMMARY When processing an multi-part mime encoded email the text and/or HTML body parts are declared encoded as UTF-8 but when we try to process the message we encounter the above UTF-8 character sequence under run error. This is caused by the content of the mime part not being a valid UTF-8 encoded text stream despite being declared as UTF-8 IN DETAIL In the small number of issues we have had this reported, it has consistently been identified that a corporate email disclaimer text that is being injected into the bottom of the mail message is injecting text that is not encoded in UTF-8. This means the message part that was previously encoded correctly now has invalid encoding, and thats why our system is unable to process the message. The error message pinpoints the problem to a specific character (see attached image for an example of this). This only occurs (from the instances that we have seen) when the mail disclaimer contains unicode characters, all of the examples we have seen have been Latin 1 extended characters that fall outside of the standard US-ASCII range. When processing mail, what we do in this situation is attach the message part as a plain text file (of obviously unknown character encoding) attachment and report the actual error in the message body and deliver the message as usual. It is generally possible to open the attachment to see the original message body content in something like Notepad. We have not been able to identify the mail system(s) that allow this type of corruption to be applied to email messages it emits but we have certainly seen it on more than one instance from time to time. SOLUTION The solution to this problem is obviously to expect mail transmitted to our system to at least be correctly encoded, so we would recommend that the organisation who is emitting these malformed messages be notified and asked to fix the problem which does not seem to be an unreasonable position. While it is entirely possible to hack something together to ignore this error, I would be uncomfortable putting a *hack* in our codebase to work around this, or ignore it only to be held accountable for not correctly handling character encoding. We have put a lot of effort into ensuing we have reliable and predictable email handling by conforming properly to well defined and ratified standards. Getting the error message we report on this specific error condition to be so accurate and precise took time and effort, and we were really being forced into that because in the absence of this level specific error understanding and reporting we were being held accountable for these failures, with claims like, it works ok on Exchange/Outlook so it must be your systems In the statement that we have communicated to you with regards to any "limitation of the current component support for different character sets used in emails" we probably have not communicated this correctly - its not a limitation as such, its an inability to make sense of incorrectly encoded data stream, because - well, its an incorrectly encoded data stream! With regards to "The same emails are readable in Exchange/Outlook" its probably Exchange thats emitting the incorrectly encoded messages in the first place, so it would not be surprising that it could handle such a situation, but that does not mean that Microsoft have got it right, the standards are really clear about this and the error condition is very easily demonstrable - so maybe a moral dilemma there - should we hack our own system and make it ignore the broken errors because Microsoft Exchange does? and if we do, what do we tell the next customer that complains that our system breaks their email because their disclaimer text no longer shows the missing characters that we have to ignore to fix the broken stuff, in the eyes of anyone else looking at their malformed message is going to blame us for breaking their mail. Or perhaps we "pass it through" as is and ignore the UTF-8 errors, then what happens in the various browsers that people are using, what errors will they throw, or what malicious XXS code could get injected as a result of us passing invalid utf-8 streams into the browser, or what if the browser starts reporting encoding errors, or makes the message when you view it in the browser show corrupt or mal-formed content - these are all things that we would be expected to fix. The only correct answer to this is to fix the source, we have considered every other possibility and that was our conclusion but I am happy to have a debate should yourself or anyone in the community that wished to contribute their views and thoughts. Gerry

-
Hi Martin, Just to clarify, the specific issue is relating to UTF-7 encoded emails which our mail servers are unable to process? UTF-7 is a somewhat esoteric encoding scheme "proposed" but never actually standardised. Please correct me if this is not the UTF-7 encoding issue? If it is, then the rest of my comment applies, if not please ignore me and see next post below You can read more about it here on Wikipedia: https://en.wikipedia.org/wiki/UTF-7 But I will draw your attention to this specific paragraph, where it states... Now we do our very best to adhere to all standards, but UTF-7 has never made is as a standard, mainly because it really does not offer anything useful that cannot already be achieved with UTF-8, yet its use would likely create lots of interoperability issues because of the complexity and ambiguity in its specification, and thats why the IMC recommends against its use which is why we do not support it. UTF-7 also opens up possible security holes which make it possible for ASCII escaped unicode blocks to slip malicious strings past the UTF-7 processor, there is a known XSS issue in older versions of Internet Explorer that does exactly this It would be good to understand where mail with this encoding scheme is originating from, we process an awful lot of mail messages on our platform every single day but we very rarely see this problem. Is it possible to inform the originator of these messages and see they can change their mail system config to use something more aligned with standards? Also, can you confirm that you still receive the messages, but the message body is just added to the mail you receive as a text file (thats what should happen) Hope that makes sense? Gerry
-
Applicaiton Rights to assign/complete other users activities
Gerry replied to Martyn Houghton's topic in Service Manager
By way of a quick update on this one. We have expanded the tasks implementation to provide a "hook" for individual applications to have more control over tasks created within their application, including the ability to use their own business logic to determine if the owner of a task can be changed, and by who. The first stage of this is the core hook and has already been implemented and is in test, this should be out on dev and beta within the week ready for the Service Manager application team to pick this up and add the ability to to allow this. The effect will be that tasks created against requests will be able to be completed/reassigned by any user based on the application logic implemented in Service Manager (based in this case on who has visibility of the request to which the task is assigned). So you should expect to see this capability rolled out in the next 2.3 weeks. We are sorry this has taken a little while but this involved changes at multiple layers of our stack and such changes need co-ordinating between teams. Gerry -
Hi Martyn, Thanks for the clarification, ok I understand. The issues with 2.36.x are I hope an unusual situation and not the norm so I would encourage you not to consider changing your approach on that experience alone. We have been working internally to ensure we do not run into the same problem again, I would like to consider this a one-off at least at this point. Just drawing back on the ethos of Continuous Delivery, being conservative in deployment and CD are not really compatible, as soon as we are having to support multiple versions we are back into the sticky world of slow and painful updates, and projects for our customers to undertake, which as you say will involve test environments and conservative management overhead - back to the world of on-premise software Gerry
-
Hi Martyn, There is an option on the API to do this but we would not recommend this for a number of reasons. 1. We do not test selectively updating like this, we test forward only updates. 2. We will be at some point removing the "Update" button all together so application updates are pushed automatically in the same way as the platform is. The presence of the Update button is already misaligned with our Continuous Delivery policy and in some cases this is adding delays because some customers are not keeping their instance up to date, we have an audit function so we can see the range of builds in production and we have to test (or at least consider) the update from that build to the latest. Obviously as more customers are taking up the service there is a more of a spread of these and we are less able to push updates easily - which ultimately is bad for everyone. We have not yet removed the Update button because we still have some refinement of our own release process/testing/deployment to complete but that was always the intention. Maybe you can give us some sense of why you would want to do this? Gerry
-
Paul, The process tracker shows three nodes (Capture5) because each stage needs a destination so the progress bar makes sense. Does that make sense? Gerry
-
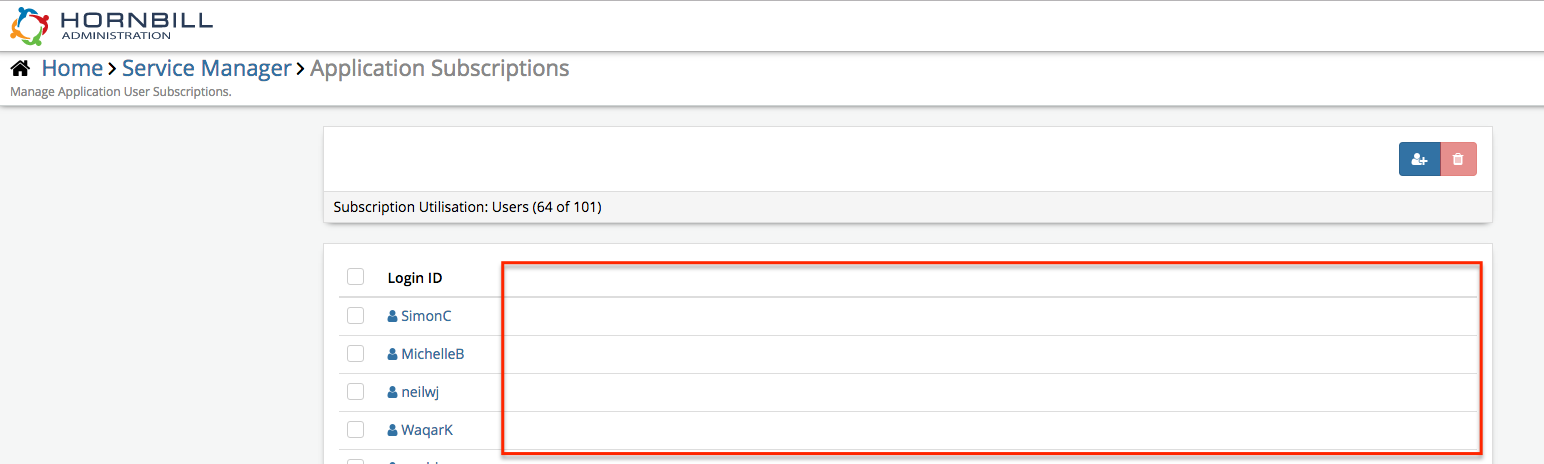
Hi Nasim, I don't have access to your system to log in, we are pretty strict about that around here I will ask one of the guys to take a look into your logs and see what is occurring. We have verified the above fixes on other instances are working fine so not sure what exactly is going on here. It looks like you are completely bottomed out on your subscriptions though so perhaps thats the problem.... We are also going to expand the following view to include the users Full Name, Job Title and Last Logon Time... these columns will be sortable, this should give you what you need. Gerry
-
Hi @nasimg, Yes that was the case, however, please see my previous comment, the source will now differentiate between normal and basic users logging into the service portal. You can of course use the reporting feature in admin to report on this data. Hope that helps. Gerry
-
@Alex8000, Sorry for the delayed reply, I had to look into it. The problem would appear to be you are using "Basic" users and this security logging was not differentiating between Users and Basic Users. This has been addressed now so the h_source column will contain one of the following values, this should give you what you need. enum securityEventSource { GuestLocal = 0, GuestSaml = 1, UserLocal = 2, UserSaml = 3, System = 4, BasicLocal = 5, BasicSaml = 6 }; This will be in the next core service update which is currently taking about 5 days. Gerry
-
@Alex8000 you can differentiate between guest and user logins with the h_source value defined as follow: - enum securityEventSource { GuestLocal = 0, GuestSaml = 1, UserLocal = 2, UserSaml = 3, System = 4 }; Gerry
-
Nasim, In most cases, customers don't create basic users, the admin is generally used to create normal users. Basic users were an "add on" to support the unified mapping between a portal user and a normal collaboration user which is why the input defaults to user. Gerry
-
Its generally not a god idea to use the <div> option when embedding remote content. CORS will stop it from working. IFRAME is the only way to go for this specific requirements. As @James Ainsworth suggested this is the URL you should use in an IFRAME. Gerry
-
Hi Nasim, Yes by the sounds of what you are saying, this is definitely one of the issues we have resolved. There is also another partly related problem that is caused by the LiveChat app, that is also fixed but will not be in live until the end of this week, but that does not appear to be affecting you so I expect tonights update will resolve your issue. If you are still seeing the problem tomorrow please let us know and we will get on it right away. Thanks, Gerry
-
Hi Nasim, There was an issue we found where the last user was not being correctly allocated so this may well be that problem. An update is rolling out this evening which includes the fix to that so I expect this will be resolved first thing in the morning for you. If not I will make investigating this a priority for the team and find a workaround. Hope thats ok. Gerry
-
Story: Migrated from HP Service Manager to Hornbill and went live in just 8 weeks! I was delighted to receive a lovely email from one of our new customers today. The organisation operates globally with about 330 people working in IT. Previously they were using HP Service Manager which had limitations for them, they were keen to look at SaaS solutions for its replacement, we were competing for the business along side ServiceNow, Cherwell and HP Service Anywhere, they properly evaluated ServiceNow, HP and Hornbill. This is a fairly large deployment with 170 primary IT users and another 160 collaboration users who also contribute to IT service delivery as and when required. EDIT: The full case study is published here: https://www.hornbill.com/blogpost/crown-packaging-modernizing-enterprise-it/ The big win for me is how well our deployment methodology works for our customers. The base implementation services for our solution is always delivered free of charge, as was the case here, but the customer also wanted to purchase additional services to help move things along and get every process they needed built, tested and deployed. The extra services required amounted to 6 days (in terms of both effort and cost). I should also say at this point that the customers own implementation team are excellent and that certainly made the difference to the project's outcome. Our technology and our methodology for implementation makes this possible and I believe we are unique in the industry because of this capability, the days of huge consulting projects to put a service desk into production are well and truly a thing of the past. Of course I can say this, but the best way to get this across is to let the customer do the talking….this is what he wrote to me… I have kept the organisation and contact anonymous for now to keep media approvals simple, a more formal success story with more detailed facts and figures as well as the identify of the organisation will follow. For now though I was keen to share our success.
-
Applicaiton Rights to assign/complete other users activities
Gerry replied to Martyn Houghton's topic in Service Manager
All, The plan is to provide different behaviour for task completion when you action a task from *within* the request view. We will be adding Service Manager application logic that will internally elevate for the purpose of allowing the task to be completed, we will probably add an application right to control this behaviour. I will follow up with SM DEV team and get someone to post an update Gerry- 52 replies
-
- 1
-

-
- applicaiton rights
- assign
- (and 2 more)
-
@Alex8000 as you can see from the post above, this was a setting that we had to change, I had a feeling that might be the case. Please let us know if this is not resolved. Gerry
-
I recently posted a security update blog article. https://www.hornbill.com/blogpost/dirty-cow-security-hole-discovered