davidrb84
-
Posts
254 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Enhancement Requests
Everything posted by davidrb84
-
so everyone's on the same page, we're also hoping to run a large user import very soon, but am waiting for someone to agree we should use the force=true flag before we do. I'm obviously loath to do this import while we're also seeing these issues of unknown cause. Any comment on if we should do that import or not while investigating this would be welcomed @Victor
-
hi @Victor for the abundance of clarity, we have NOT yet carried out a mass import. When we ran an import of 1 user this did not reset the flag, as this does not match your expected behavior above I do not want to run a large import and risk causing havoc. We will run the large import with the force=true flag if you think that appropriate.
-
Thanks @Pamela @TrevorKillick we do appreciate the team's hard work.
-
Hi @Pamela @TrevorKillick just to clarify, approx 1 in 3 jobs we're logging are being lost currently, requiring re-entering from scratch. This means we're having to double record all jobs, so that we don't lose the information when it fails, this is start of term, and a massive problem.
-
thanks @Pamela appreciate your continuing to look, so you know I'll be sending the team home a little early tonight as they're having so much trouble logging (about 5). I'll continue to monitor this post though this evening.
-
For completeness this is still ongoing, errors on multiple attempts, usually successful after a few minutes of several attempts. For context, we're logging (or trying to) ~3-500 requests a day at the moment. @Pamela
-
replicated actions exactly 30 seconds later and this succeeded with no error.
-
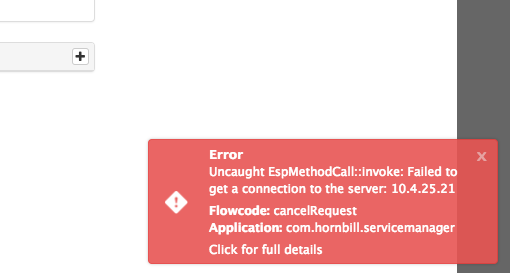
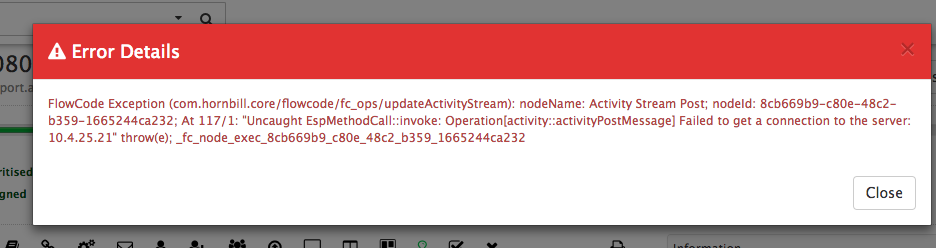
Just for reference, error below received when cancelling a request as duplicate a few moments ago.

-
@Pamela looks like we're getting this intermittently still, let us know if we can provide info/logs/etc.
-
+1 too for us please.
-
@Pamela We had top and bottom enabled, both are now disabled.
-
I believe last time the infrastructure team found an issue with the indexing service?
-
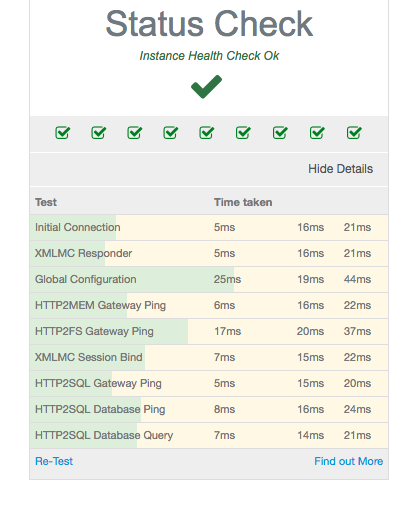
I get an error as below The support portal shows successful pings from all resources
-
we're getting errors on job log, update, and cancel jobs. Again. We're going to start recording the errors so we can see if there's a pattern. We currently cannot create new requests
-
I'm aware at the moment if you don't specify a team the views limit the result to 'your' teams. You can specify all the teams individually which will show jobs in all teams. However, this means entering all the teams, for all the views. We create a template of all teams which helps, but a meta group called -all-teams would be really helpful. What do people think?
-
thanks @Victor as above, we ran the last run with 1 record, this did not reset the flag to successful (subsequent attempts errored saying it was already running) although it claimed to have been successful.
-
@Victor also we've been scheduling the student imports for nighttime as there are alot of records. Do we need to be so cautious or will the import process either backoff if loading becomes a problem, or does it naturally work sparingly?
-
@Victor should we be concerned that we're routinely overriding what looks like a safety mechanism?
-
Failed to log request and failed to connect to server errors
davidrb84 replied to davidrb84's topic in Service Manager
@Victor looks like we're back again now. Is this related to the longer outage we had on the 5th September? -
Failed to log request and failed to connect to server errors
davidrb84 replied to davidrb84's topic in Service Manager
@Victor looks like the 10.4.25.21 is unreachable from here, but also unpingable from external. (don't know if you would expect it to respond to ping) -
Failed to log request and failed to connect to server errors
davidrb84 replied to davidrb84's topic in Service Manager
errors connecting to server on trying to update job.
-
populate the TO: field in emails based on connection type
davidrb84 replied to davidrb84's topic in Service Manager
@James Ainsworth that's fair, but if you click on the email tab within the request, and they populate the to: field, and you click send without realising, then there's not much the system can do to avoid that :-) Also, if it's only a given connection type, if instance owners have an issue with how that works they can use a different connection type. -
failed to log request, also users reporting failed to connect to server errors. Looking on support portal all pings succesful.
-
thanks @Keith Stevenson I wasn't aware of this, if it happens again I'll try that tool.
-
Afternoon all, We just had an unresponsive instance for about 3-5 minutes. It's back now, but wanted to pass on the outage.