

David Hall
-
Posts
653 -
Joined
-
Last visited
-
Days Won
34
Content Type
Profiles
Forums
Enhancement Requests
Posts posted by David Hall
-
-
Hi @simonadams
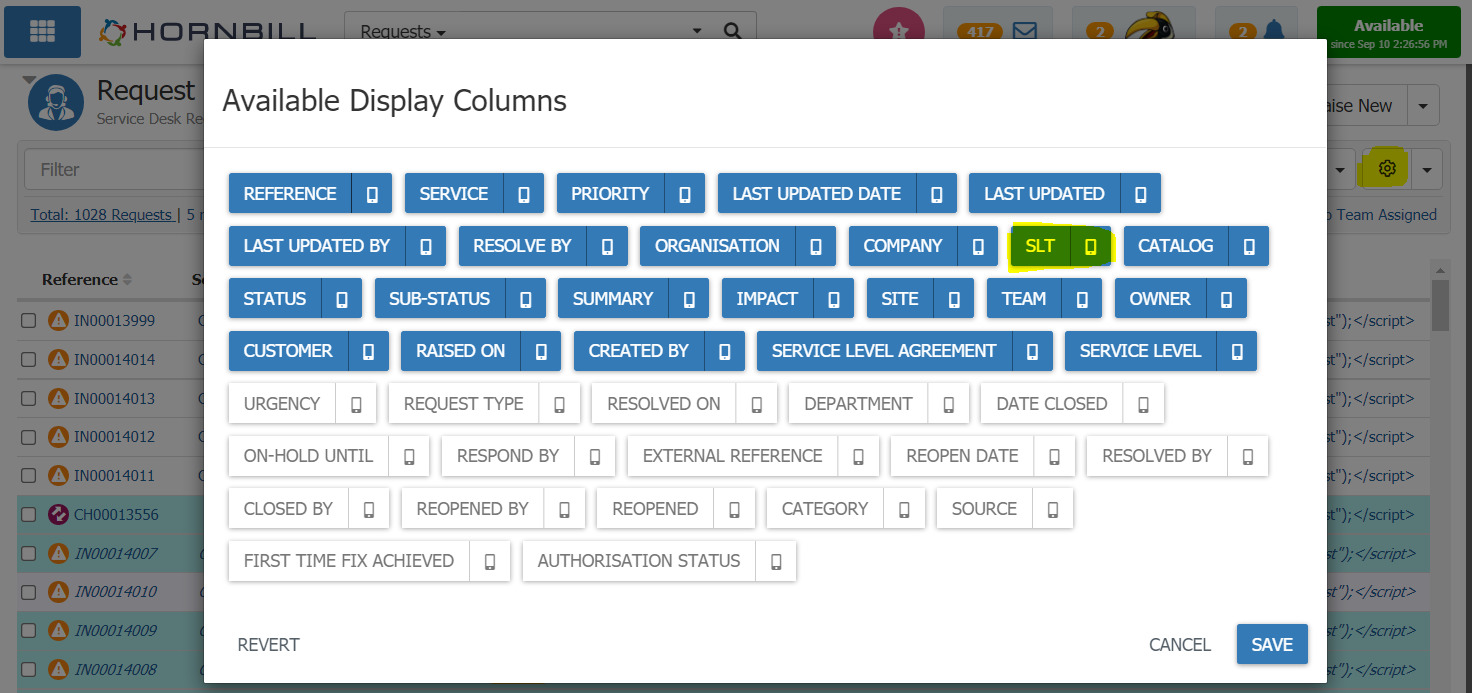
From the Request List view if you click on the cog at the top right to configure the available columns, there is a column named "SL" or "SLT". If you select that column to be available in your view then you will see the indicator dots made available. These will alter in colour based on the current state of the service level timers you have running against the requests.
Hope that helps,
Kind regards,
Dave.

-
I've still not been able to fully replicate locally but I have a suspicion it could be down to the fact the request was raised out of working hours and then escalated immediately before any time elapsed. I'm just trying to recreate that scenario to see if I can confirm whether that is the reason for the resolution time being incorrectly reset. Will let you know when I can confirm or not.
Kind Regards,
Dave.
-
Thanks @Rashid.Ahmed I'll take a look to see what I can find.
-
 1
1
-
-
Hi @ALIPO
You should be able to click from the Hornbill Main menu choose "Customers" -> "Organisations" and add from there
Kind Regards,
Dave.
-
Just to check.. are you using the BPM nodes to control the pause/resume or are you using the app settings e.g. app.request.pauseResolutionTimerOnResolve to do it automatically?
Kind Regards,
Dave.
-
Sorry I've been on leave hence the lack of recent reply. Based on the debug info you have posted let me review and see if I can determine what is happening in this scenario.
Kind Regards,
Dave.
-
It does look incorrect but its pretty hard to confirm from the screenshot, sometimes changing an SLA after a target has already been missed etc can result in this view for example.
If there has not been an SLA change to cause this scenario, if you have the "Incident Management Full Access" role you should be able to click on the blue button under "Service Level" to open the SLA update popup. To the bottom right of the popup there is a diagnostics button which will show a list of the primary SLA actions e.g. pause/resume etc. It might be worth checking that to see if that shows when the pause and resume took place and when the resolution/fix target was marked to see if that highlights any reason for the above.Kind Regards,
Dave
-
@Michael SharpI've just reviewed this and can see the reason.
To clarify, the h_withinresponse value (and h_withinfix value) are only set when the target is confirmed as being within or outside of the target time. This has always been the case and continues to be so.
Regarding your question on this request, if I read the screenshot correctly, the target response time was 12:05, the target was missed and then at 12:06 the SLA was changed which altered the time to an hour ahead. In this scenario because the target had been missed at the point at which the SLA was changed, we set the h_withinresponse to 0 hence why it will not be appearing in the results. If the SLA change was made before the target time then the value would have remained as null.
Hope that clears it up,
Kind Regards,
Dave
-
You should be able to use a formatter on the template to format to local time as follows {{.H_pk_reference|formatLocalTime}} . Full details of email formatting can be found here https://wiki.hornbill.com/index.php?title=Email_Templates
Hope that helps,
Kind Regards,
Dave
-
Hi @ALIPO
Sites are managed via the admin tool.. full details can be found here https://wiki.hornbill.com/index.php?title=Sites
Hope that's what you are looking for...
Kind Regards,
Dave.
-
I've reviewed the code and currently months are as you say just being determined as a 4 week period, this is likely just a legacy choice due to ambiguity over what is defined as a month e.g. 28 Days in Feb/31 Days in March etc.
I'll make an enhancement to this flowcode so that when you are defining months and we are not working against a working time calendar, we will treat "a month" as the same day in the following month etc.. so in your example 26th Feb will become 26th August, however there will of course be some exceptions e.g. adding 1 month to Jan 30th with result in March 2nd rather than a non existent February day.
All of the datetimes are calculated and stored in UTC and formatted in the UI according to your regional settings, so the value is not one hour ahead in the database it is just being displayed as one hour ahead due to being in BST at the date in August.
As an alternative until this is available you could:
1. Apply a number of days e.g. 182 days for 6 months or any of the smaller time denominations as @Victor suggests above (accepting the calendar day may not match)2. If you have any way to make the exact date available to the BPM at that point (e.g. a date selected custom field on a request) then you can pass in an exact date to the "On Hold Until" parameter of that flowcode which allows you to set the exact datetime.
Regards,
Dave.
-
Just an update, I've identified the issue which sadly does occur when just using the settings as you have configured. I've implemented a fix for this and we'll get that included in the next Service Manager update (build > 2143).
Kind Regards,
Dave.
-
Hi @Mark (ESC)
These values are automatically populated when you mark the response/resolve timers when using service levels. So provided you have a response and/or fix timer in use against a request, when the timer is marked as complete it should store a value here.
Hope that helps,
Dave.
-
1
-
-
Thanks for posting back, I've been having a look into this issue following James' comment and it looks like there may be an issue when using the settings rather than BPM to mark the resolve time on resolution. I'm currently investigating and will post an update back here as soon as I have confirmed the issue and have a way forward.
Kind Regards,
Dave.
-
 1
1
-
-
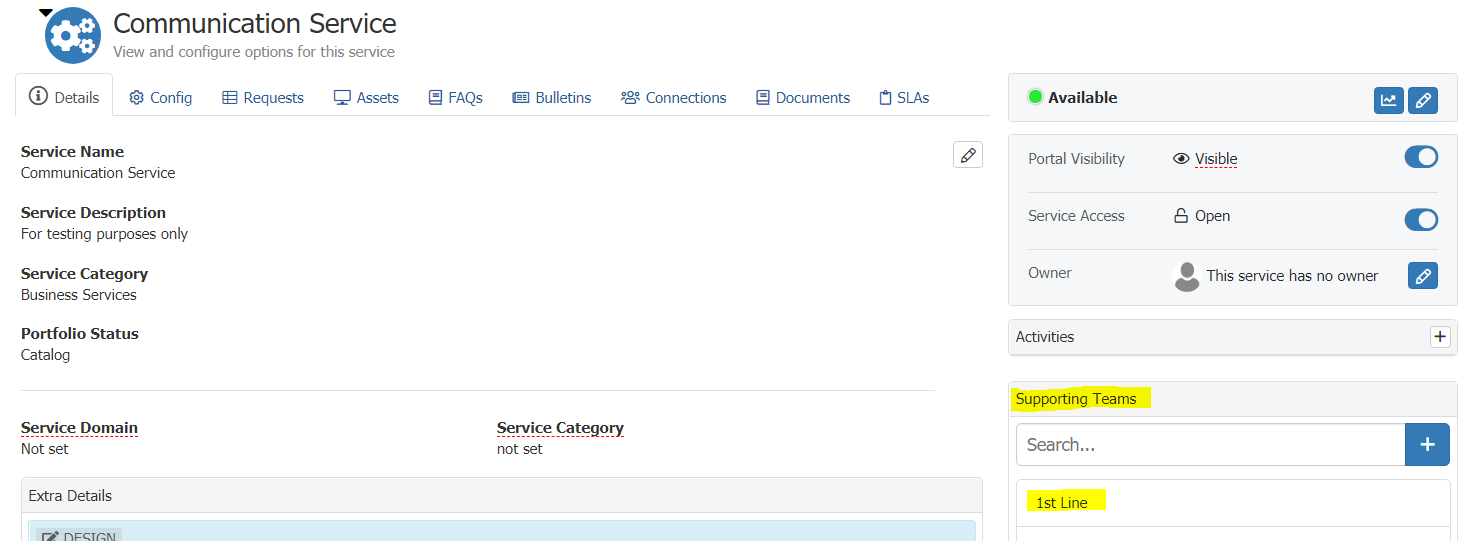
Hi @JamieMews
As detailed here https://wiki.hornbill.com/index.php?title=Service_Support_Teams all services will be supported by all teams (hence visible to all) until you add teams into the "Supporting Teams" within the service configuration view e.g.
Once done requests for that service will only visible to analysts within the specified teams.
Hope that helps,
Kind Regards,
Dave
-
From the numeric id in brackets I wonder if these are guest/customer accounts? Do they show up in the admin tool as shown in this screenshot?
If no luck here on in the user accounts list then it would probably be one that will need support to investigate on your instance.
Kind Regards,
Dave
-
Yes SLAs work in the same way across all request types. Martyn provided some good areas to check, if no luck there then we can look for more configuration areas to check.
Kind Regards,
Dave.
-
1
-
-
Hi @Jeremy
Just wanted to check if you are still experiencing this problem? Checking the error, the only reason it would likely occur is if the ID value of the service was not sent when it tried to do the update... so just wanted to check if something had not refreshed correctly after you added the field etc. or if the issue has persisted. If you still have the problem, if you could outline the steps you took to encounter the error and we can see if we can replicate.
Kind Regards,
Dave.
-
Thanks for feeding that back, I'll speak to James regarding the best location to place the information you mentioned. I suspect we'll place in somewhere with a link from the nodes page here.
The information I plan to add will be as follows:
Pausing/Resuming/Stopping the Resolution timer
By default the settings are configured to provide no change to existing behaviour whether you use BPM or settings to control timer resolution
The settings provided to pause or stop the resolution timer when resolving a request are as follows:
app.request.pauseResolutionTimerOnResolve (Default OFF)
app.request.resumeResolutionTimerOnReopen (Default OFF)
app.request.stopResolutionTimerOnResolve (Default ON)
app.request.stopResolutionTimerOnClose (Default OFF)For those using settings to control resolution timers:
You should choose the relevant settings to meet your needs, but note that app.request.stopResolutionTimerOnResolve will take precedence over app.request.pauseResolutionTimerOnResolve so ensure only the one you want to use is enabledFor those using BPM nodes to control resolution timers:
If you are using BPM nodes to control resolution timers the four settings above should all be turned off; If any settings are enabled then they will take precedence over BPM actions.
To enable pause/resume of a resolved request you can add the Timer > Pause Resolution Timer or Timer > Resume Resolution Timer BPM nodes as required in your BPM process.
If you have any feedback or if there is anything unclear then let me know and I can make any suitable adjustments.Kind Regards,
Dave.
-
Hi @JoanneG
Thanks for the post. Firstly it sounds like a request custom field would be the likely way forward here, this would keep the value stored against the request, allow you to report/filter on that value and perform escalations based on that value.
Whether you use progressive capture to populate that data really depends on where you are able to capture it. If you want the person raising the request to select the ward from a list etc as part of the raising process then a progressive capture custom form https://wiki.hornbill.com/index.php?title=Customised_Forms could be used to do this and you can map that selection into a request custom form as detailed here https://wiki.hornbill.com/index.php?title=Mapping_Fields_from_Customised_Forms
On the other hand if you have any means to automatically determine the ward then you could automate the population of the value from within a BPM process, again populating the custom field which you can then use to filter etc.Hope that helps, if you need any more info just post back.
Kind Regards,
Dave.
-
1
-
-
Thanks for the post. If it is just some cases that create new calls while most correctly update then the most likely cause as you say is that a rule above it is being processed first (rules will be processed top to bottom) which is set to create a call or perhaps the expression did not match on those specific calls and you would need to check that the request reference is being correctly matched.
You probably already have checked here, but just for reference I'll point to the docs here https://wiki.hornbill.com/index.php?title=Email_Routing_Rules , might be worth checking the last couple of lines regarding reference in the routing rule if you are using the mentioned operations.
Kind Regards,
Dave.
-
1
-
-
Hi @Mark (ESC)
Just trying this out locally, all appears to work for me with the attached configuration, however I am able to replicate that error you posted when I change the email template name to something invalid. As a starting point I'd probably double check that the defined email template still correctly exists with that name in the admin tool at Home > System > Email > Templates, if that looks ok perhaps test with a different or new template to see if that has the same issue?
Kind Regards,
Dave
-
This message will appear on inactive processes which contain custom forms that have had changes made since the form node was added into the progressive capture. The message is to explain that form changes e.g. addition/removal of fields will now be reflected in the available fields in the form node but these changes will not take any effect until you save/reactivate the process.
Hope that makes sense?
Kind Regards,
Dave.
-
I've just checked and unfortunately these are currently a fixed list of set options rather a simple list, I suspect because they needed to be translatable and this was not possible originally with simple lists.
If you have specific options that you would like added then perhaps you can post them up and @James Ainsworth can have a look whether we can raise a change to incorporate those into the existing fixed options list or possibly migrate to use of a simple list in the future.
Kind Regards,
Dave.

New UI suggestion
in Service Manager
Posted
Thanks for the feedback @Paul Alexander
I've passed it on to get this looked at.
Kind Regards,
Dave.